Measures of Software Success
Tags: devops software development digital transformationSoftware is eating the world.
Marc Andreessen chose his words carefully in his 2011 WSJ article. He didn’t say “information technology” or “computers” are eating the world - software is eating the world.
The convergence of cloud computing, Moore’s law and modern software practices mean that digital solutions can be deployed with little to no investment and reach out to a global Internet market of US$4 trillion.
From the FAANG giants of Silicon Valley you can add logistics titans like BestBuy, Walmart and FedEx who have used software to crush their opposition, financial services like Square and Paypal and in our region companies like Atlassian, Canva, Dominos, Air New Zealand, Xero and UBank.
And in the world of ‘cloud computing’ - hardware is software. All cloud resources are now ‘code configurable’, that is they can be spun up from a code template on demand. No longer do engineers have to rack hardware for a project, instead a developer can deploy a server or service from a code pipeline and it will be spun up on commodity scale compute resources anywhere in the world.
This has the added advantage that the hardware configurations are ‘immutable’ - they are defined in the template and do not change, until the template is changed and they are redeployed; which prevents ‘configuration drift’ or unintended changes.
So the brave new world is software-defined and software development is the key to your golden future. But if you are not intimately familiar with software development, how do you gauge its efficiency and effectiveness?
It turns out that there is a well trodden and statistically proven set of metrics.
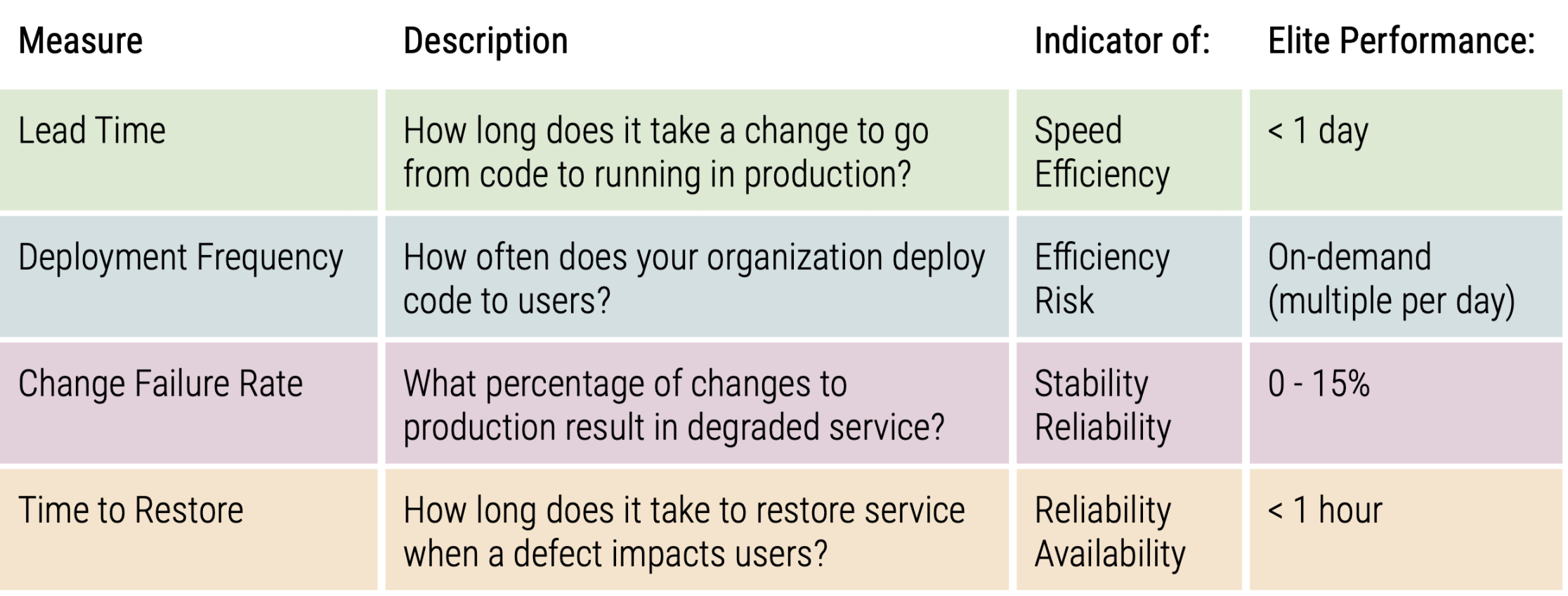
Four measures of software development - lead time, deployment frequency, change failure rate, time to restore
These metrics are drawn from the 2019 State of DevOps report released by the DevOps Research Association (DORA, now part of Google). Based on responses from 31,000 professionals worldwide, the study used cluster analysis and structural equation models to group respondent organisations into low, medium, high and elite performers. It also draws strong statistical links between software development performance and organisational performance (including profitability, productivity, and customer satisfaction).
Lead Time

Software development is a creative process.
Like all creative processes, the first and most complicated step is to decide exactly what to build. Whether you take a rigid process and specify requirements or ideate through rapid prototypes, the decision cycle is typically flexible, flawed and highly variable.
But it’s not a good predictor of software development performance in any case.

Excluding the ‘fuzzy front-end’ of software development and measuring the time it takes from when a developer commits a change to software, to the point where it is deployed in production gives you a robust correlation with software development performance.
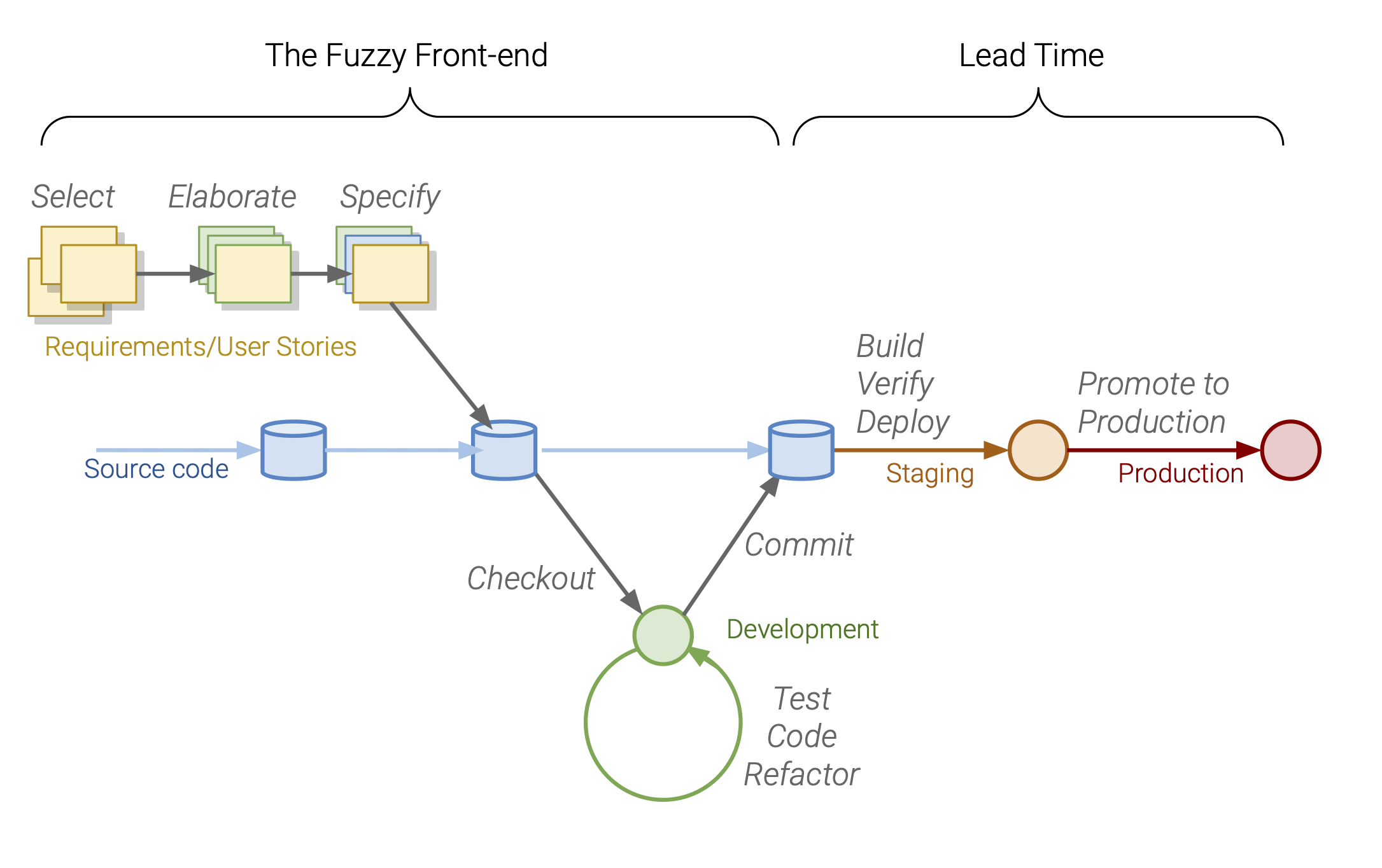
Lead time is often constrained by bottlenecks in the deployment process. Sometimes these are manual gates or processes (like change management) and sometimes they are automated, like lengthy automated test cycles.
These can typically be exposed by shifting to smaller and smaller changes, deployed more frequently – in Lean circles this is known as “lowering the water level to expose the rocks”.
As our CTO Tim Myerscough is fond of saying, “if it hurts, do it more often, and bring the pain forward” because you will find ways to reduce the pain.
Once you have found the bottlenecks you can move towards continuous delivery and integration by :
- Automating nearly all the testing with a focus on minimising deployment times
- Removing all manual steps in the deployment process
- Investing in code maintainability
- Shifting to trunk based development to reduce ‘inventory’ code on ‘dead’ branches
- Adopting a lightweight and clear change process
Collectively these will bring your lead times down to the point where you can confidently deploy multiple times per day.
Deployment Frequency

Higher Deployment Frequency leads to better efficiency and reduced risk in Software Development
There’s an idea in traditional IT that I like to refer to as “risk management theatre”. Hurdles are placed in the way of anyone wanting to change production on the basis that to change production is complex and therefore risky.
These hurdles typically involve people sitting around in rooms reading documents about what the change is supposed to do and how it will be executed. Note that they do not review the actual changes themselves, in code or hardware, just various process artefacts that represent the change. This typically adds hundreds of hours of effort to a change.
The result is that it becomes economically infeasible to deploy small changes. So changes get larger and larger, adding more and more complexity (and risk) to each ‘release’ in order to compensate for the cost of ‘change management’.
In contrast, there’s a concept from Lean Manufacturing with the unlovely acronym of SMED - or Single Minute Exchange of Dies. SMED while doing the laundry - Single Minute Exchange of Dies
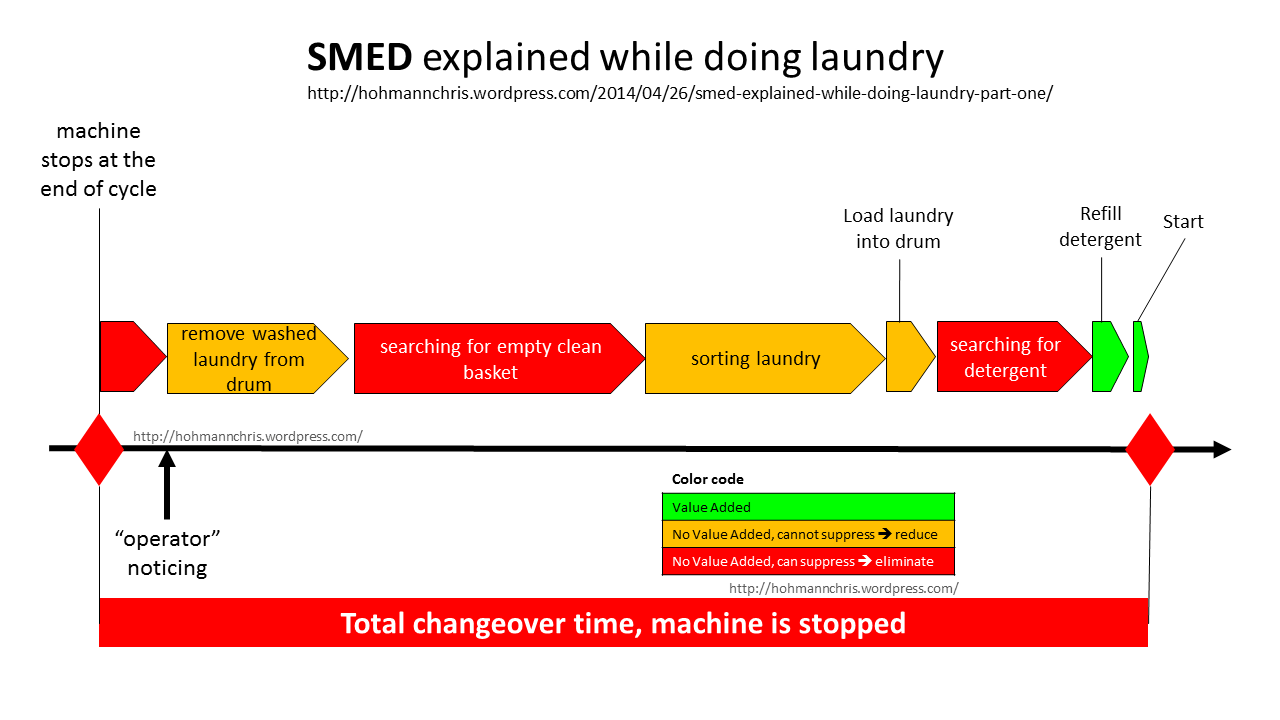
In car manufacturing, large sheets of metal are pressed into doors and bonnets by huge metal presses weighing several tons. You can do hundreds of panels an hour, or more. Changing over the die, or the shape of the metal however is hard, it requires hours of down-time to change and recalibrate a press.
Or so the thinking went.
A few people at Toyota looked at the problem and asked the question : why does it take so long to change over a press? Can’t we do it faster?
And that changed the whole mindset.
In Toyota and other auto manufacturers around the world, they regularly changeover the die on a ten ton metal press in less than 60 seconds – Single Minute Exchange of Dies.
The software development analogy to changing a die press is the build and deployment process. If you decide that the smallest unit of code you can write, test and deploy is one line then you:
- minimise complexity
- minimise the chance of different changes conflicting with each other
- minimise risk
- maximise throughput and efficiency
And if you automate the process you bring a level of repeatability and stability that manual processes cannot match.
It’s also important to realise that you can decouple the software deployment process from the release of functionality (to users). Having code in production does not mean that it is available for users, just that it’s not sitting around cluttering up pre-production environments and multiplying the complexity of making code changes. Using patterns like ‘feature flags’, changes can be deployed incrementally and then switched on at the appropriate time.
Change Failure Rate

Software changes fail for a number of reasons.
Sometimes the environment in which they were built doesn’t accurately reflect the environment in which they are deployed. Sometimes the engineer deploying the change hasn’t adequately considered the context of the change and has omitted to design or test for a particular consequence. Rarely they conflict with another, parallel change to the target environment. Often they fail because of mundane errors in the code, pipeline or configuration.
Amusingly IT changes in largely manual change processes rarely fail. Because of the stigma and opprobrium attached to a ‘failed’ manual change, people avoid having them seen to fail. If the first piece of manual tinkering fails to work, more and more manual tinkering is deployed in order to make it work - with each successive iteration drifting further from the pre-arranged script - change management theatre at work again.
Data from the 2019 State of Devops report indicates that change failure rates range from 0-15% for Elite, High and Medium performing software organisations to 46-60% for Low performers.
A change failure rate of 15% (or about 1 in 7) might seem quite high for an ‘Elite’ performing team, but it should be remembered that these teams are deploying small changes multiple times per day, compared to about once a week for High performers and once a month for Medium. The cumulative risk is exponentially lower.
Low performing organisations are facing what is known as ‘special cause’ variation - that is they are part of a process that isn’t under control and can’t be controlled. Essentially low performing organisations are rolling the dice every time they make a change and it is about as likely to fail as it is to succeed.
And remember, this is a measure of how the change succeeds at the first attempt. Organisations with manual change processes rarely measure this accurately, it is only by automating them that you get a clear picture of what is happening.
By automating the process you begin to identify and remove the special causes until you get to a point where the exceptions are generally well known and identifiable.
Time To Restore

A shorter Time to Restore leads to better Stability and Reliability
Even with the best change management practices, disruption is inevitable.
The complexity of software means that even minor configuration changes or unexpected combinations of state can lead to errors or failures in some components. In well-architected systems this leads to a degradation of performance, in more fragile systems it can lead to outages.
One of the benefits of automating your deployment and using frequent small changes is that it gives you the ability to automatically rebuild and deploy your application at any point. Because all of your changes are captured sequentially in source control you can effectively ‘play back the tape’ and stop it just before the error was introduced. This assumes of course that you have everything configured in code, including your infrastructure configuration.
But no process is perfectly deterministic however and so this should be tested regularly. Minor changes and unexpected complications can thwart your ability to rebuild on the fly. Testing it will give your teams the confidence and experience to cope with unexpected complications and restore service quickly.
Just like backups which are never restored, a disaster recovery plan that is only enacted the first time disaster strikes is likely to compound the problem (if the worldwide COVID response hasn’t convinced you on this point, nothing will).
To reduce the time taken to restore systems:
- Have a clearly understood process for changes
- Organise disaster response exercises using cross functional teams to strengthen communications
- Learn how to conduct rigorous but blameless post-mortems
- Practice disaster recovery and learn from the exercises
Conclusion
Beware the trap of confusing measures with targets.
Managing by numbers went out of favour some time in the 1980’s . At least is should have. A striking proportion of managers still cling to the idea that they can improve things through goals and exhortations.
Edwards Deming summed it up best in his 1986 book “Out of the Crisis” (p76):
"If you have not a stable system, then again there is no point in setting a goal. There is no way to know what the system will produce.
"To manage, one must lead. To lead, one must understand the work that he and his people are responsible for. Who is the customer (the next stage) and how can we better serve that customer? An incoming manager, to lead, and to manage at the source of improvement, must learn. He must learn from his people what they are doing and must learn a lot of new subject matter.
"As we have already remarked, management by numerical goal, is an attempt to manage without knowledge of what to do, and in fact is usually management by fear."
So you must learn. You must learn what works and what doesn’t.
How?
By observing the system through the numbers it produces, by hypothesising and experimenting and by replacing the rhetoric and exhortation with evidence.
Marilyn Strathern paraphrased British economist Charles Goodhart’s 1975 observation as “when a measure becomes a target, it ceases to be a good measure” - hence forth to be known as Goodhart’s Law.
Measures are valuable, but targets generally are not.
Do not confuse the system with the people in it.
By all means, measure your system, understand the numbers and what they represent. Share them widely with your people and discuss them openly and without blame. Your team’s natural inquisitiveness and pride in their work will take care of the rest.