Continuous Deployment - The First Step on Your Road to Recovery
Tags: devops continuous-delivery lean trunk-based-developmentSystems thinking, or the First Way, in DevOps is about improving the flow of work into production. Hand-offs, re-work and batching are all enemies of flow. Teams don’t intentionally reduce flow. Hand-offs and approvals are mechanisms introduced in an attempt to tackle the risks of delivery.
Continuous deployment is a goal for most teams: a lofty ambition that other people achieve. For Mechanical Rock, continuous deployment is our starting point. And continuous deployment starts with continuous delivery and a suitable branching strategy.
Your branching strategy is a fundamental decision for development teams and has profound effects upon your working practices. Making a poor choice has knock on effects that can limit improvements in other areas.
Damming the Flow
A common branching strategy adopted by many teams is git flow.

The goals for GitFlow are in direct conflict with continuous delivery and maximising flow, highlighted by the original author:
We consider origin/master to be the main branch where the source code of HEAD always reflects a production-ready state.
We consider origin/develop to be the main branch where the source code of HEAD always reflects a state with the latest delivered development changes for the next release.
Maintaining multiple long-lived branches are an inhitibor to flow. Changes queue on a branch, waiting for release to production. Divergence between branches adds complexity, the risk of regressions and merge hell. The risk grows exponentially with the number of branches maintained.
Teams choose git flow for well intentioned reasons. Faith in the codebase is low: the impact of change is unknown, caused by insufficient feedback loops. A vicious cycle develops:
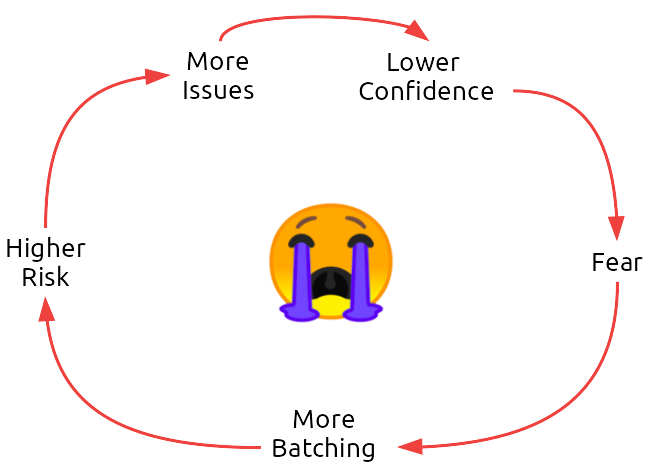
Releasing the pressure
A good practice of The First Way is one piece flow. Work on single increments of value, delivering them as soon as possible.
One piece flow - a simple idea with a simple implementation: continuous deployment. Every commit flows through your continuous delivery pipeline and, assuming all conditions pass, makes its way to production. The idea and the implementation are simple, but there are a number of fundamental principles that you must adhere to:
- You have a single pipeline flow changes into production
- You must have confidence in your pipeline to publish changes to the next stage
- In order to have confidence, you need a high level of automated test coverage.
- In order to increase flow, you need fast feedback
- In order to have fast feedback, you need a highly automated pipeline
Rather than making it an aspiration, we have found that starting with continuous deployment is the first step to maximising flow.
So important, that I’ll say it twice:
Starting with continuous deployment is the first step to maximising flow.
As Behaviour Driven Development practitioners, we like to start with the end in mind. We consider the goal we are trying to achieve, and work backwards to discover how to achieve it. Many teams consider continuous deployment as the final step in their improvement of flow. Many teams never get there, nor make the changes necessary in order to deliver it. Manual approval gates are never removed; confidence in the code remains low; automated test coverage remains poor; big batch releases are common.
Trunk based development is fundamental to continuous deployment. Good practice, such as branch by abstraction and feature toggling occur as a result.
In trunk based development, the team works from a single master branch, with short lived feature branches for managing review and CI cycles:

Making the Change
If you have a dysfunctional delivery pipeline, continuous deployment can’t happen overnight. Automatically releasing to production would be folly. Technical debt needs to be paid down in order to release the blockage. This is waste that has always been there, but changing the process will make it visible:
- Switch to Trunk Based development.
- Map out your continuous delivery pipeline from commit to
master, through to production, including any manual steps. - Remove all manual approval gates up to production deployment. This immediately highlights waste in the value stream. Issues found late in QA demonstrate a lack of automated testing; manual deployment processes increase lead times. Complex deployment and extended outages highlight an inflexible architecture.
- Introduce one piece flow from
master- if there are manual steps, this will highlight bottlenecks. - Tag every commit to
master. Use short lived release branches from a tag for hot-fixes, until your cadence if fast enough.
The Result
The goal of continuous delivery is:
To make deployments—whether of a large-scale distributed system, a complex production environment, an embedded system, or an app—predictable, routine affairs that can be performed on demand.
We achieve all this by ensuring our code is always in a deployable state
Or more simply: “if it hurts, do it more often, and bring the pain forward.”
We are consistently able to deploy changes, with confidence, to production multiple times per day. We use stop-the-line processes to maintain flow. We still have branches, and PRs, but continually look to improve and reduce their lifetime. Our system architecture is simple, flexible and decoupled: driven by the need to reduce risk. Fast feedback, through comprehensive automation, maintains our flow.
We have helped clients move from release cycles taking months, to days.
And we’re hiring!
Header image licenced by Zen Wave under Creative Commons BY-SA 4.0
{kind=link}