Getting Dynamic with Snowflake
# Snowflake Dynamic Tables DataDynamic Tables
After more than a year in preview, Snowflake finally launched Dynamic Tables for general availability in April 2024. For those of us in data engineering, this is massive as Dynamic Tables brings together scheduling and data ingestion into one setup, all in SQL. This means we can handle batch and streaming data seamlessly without needing complex infrastructure or extra tools. After implementing and monitoring Dynamic Tables for a few months with a client, here’s my take on how they’re reshaping data pipelines.
The Previous Stack
The client’s batch processing architecture in AWS was powerful but complex. At the heart of it was an event manager that triggered every minute. Here’s how it worked:
- The event manager checked each batch’s CRON expression in DynamoDB and initiated jobs on schedule.
- It pulled additional parameters for each batch from pre-configured JSON files in an S3 bucket.
- For some workflows, it even ran Snowflake procedures directly.
Whilst the abstraction allowed for heaps of customisation, it was a bit of a maze to navigate, especially for newcomers. Debugging was tough, and maintaining and scaling the stack eventually became unwieldy. We started looking for a simpler solution.

Mermaid Chart of Previous Stack
The Decision
The team was made up of Data Analysts and Data Engineers. As they were already well-versed with SQL in Snowflake, it made sense to stick with something that wouldn’t need a lot of extra learning or complexity. As our data needs grew, we wanted a hassle-free way to run incremental pipelines.
We explored incremental models in DBT, but it had its own issues:
- DBT needs a separate orchestration tool, like DBT Cloud, which costs extra and adds another layer to manage.
- Jinja expressions in DBT, while handy, added a learning curve compared to plain SQL.
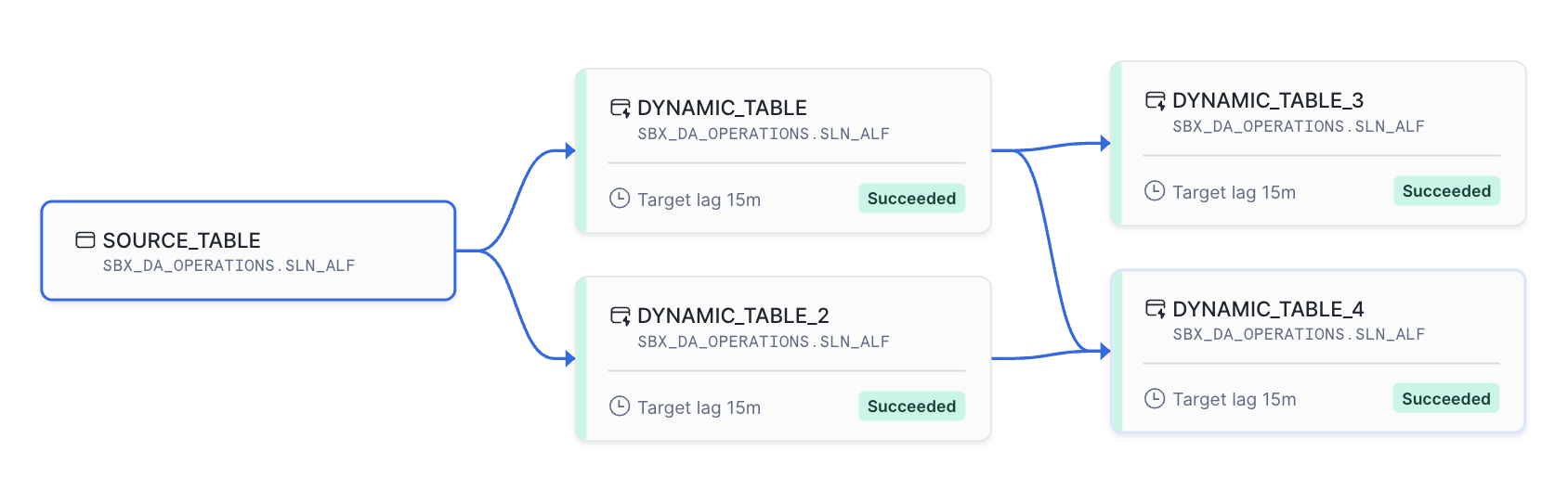
The below example shows how simple it is to create a Dynamic Table. Here, we’re creating a Dynamic Table named COMBINED_SOURCES, which consolidates data from multiple source tables and refreshes every 15 minutes (well, it actually aims for a target lag of 15 minutes). By setting the Dynamic Table to INCREMENTAL mode, it only materialises the results of the query based on changes upstream from the source data, allowing us to maintain a near real-time view without the need for complex ETL (extract, transform, and load) processes.
CREATE OR REPLACE DYNAMIC TABLE SCHEMA.COMBINED_SOURCES
LAG = '15 minutes'
REFRESH_MODE = INCREMENTAL
INITIALIZE = ON_SCHEDULE
WAREHOUSE = WAREHOUSE
AS
(
SELECT * FROM SCHEMA.SOURCE_A
UNION ALL
SELECT * FROM SCHEMA.SOURCE_B
UNION ALL
SELECT * FROM SCHEMA.SOURCE_C
UNION ALL
SELECT * FROM SCHEMA.SOURCE_D
UNION ALL
SELECT * FROM SCHEMA.SOURCE_E
);
Dynamic Tables just made more sense. They work directly in SQL, can still be version-controlled, and offer easy refresh options. This approach kept things flexible and simple without needing more tools.
Issues and Concerns
In its current state, visibility into Dynamic Table failures are limited. When an upstream data source changes or is no longer available, identifying the root cause of the failure isn’t always straightforward. We’ve explored a few custom solutions to address this, including setting up a scheduled Snowflake task that queries the Dynamic Table refresh history available in Snowflake’s information schema. Whilst these custom setups are easy to implement, they do add some overhead and aren’t quite as streamlined as we’d like.
Dynamic Tables also come with a few functional limitations. For instance, they don’t support self-merges, window functions, or pivot functions. With self-merges and window functions, the lack of incremental support means that Dynamic Tables perform a full refresh rather than an incremental one, which can increase compute time and somewhat detract from the main benefits of Dynamic Tables. Pivot functions, from what we’ve seen so far, are entirely unsupported, though this does prompt a closer look at whether pivoting is truly required in your workflow.
Takeaways
Switching to Snowflake Dynamic Tables has been a game-changer.
- Reduced complexity: No need for external orchestration tools; everything is managed directly in SQL.
- Incremental refresh: Easy to control, helping us keep data up-to-date without overcomplicating things.
- Simple onboarding: New team members can jump in without needing to learn additional tools.
- Streamlined workflows: We’re focusing more on building robust data solutions rather than wrestling with infrastructure.
- Cost-effective: No added fees for extra tooling, and we’re using resources more efficiently.
Dynamic Tables have been a great addition, fitting perfectly into our Snowflake environment and team skill set. These new objects are helping us work more effectively, and we’re excited to see how Dynamic Tables continue to support our data strategy moving forward.
If you’d like to chat or have any questions, feel free to contact me on LinkedIn. Also, don’t miss out on exploring our Data & AI capabilities here!