
Don't Burn Your Data - Freeze Your Requirements!
# Python Numpy CI/CD GitHubThe Importance of Using pip freeze for Data Engineers and Analysts
Prior to my career in software consulting, I had the (mis)fortune of working in accounting, finance, and analytics. Using tools like Excel, Python, and SQL, my only goal was to deliver value quickly. Concepts such as version control, repeatable code, and GIT were completely foreign to me. I’m sure many data analysts and data scientists can relate to.
Nowadays, I preach the benefits of version control, but remnants of my analytics background have recently come back to haunt me. When working on a feature, I have a habit of not tracking my Python dependencies until it’s ready to be reviewed. However, a recent scare in our CI/CD pipeline reminded me of the importance of investing a small amount of time in managing dependencies, which can save hours of headaches down the line.
The Stack
I was working on redeveloping and transitioning a CI/CD pipeline from CodeBuild to GitHub Actions. The new GitHub Actions workflow detects changes in the source code files, which then triggers a rebuild and re-deployment of the application image to AWS.
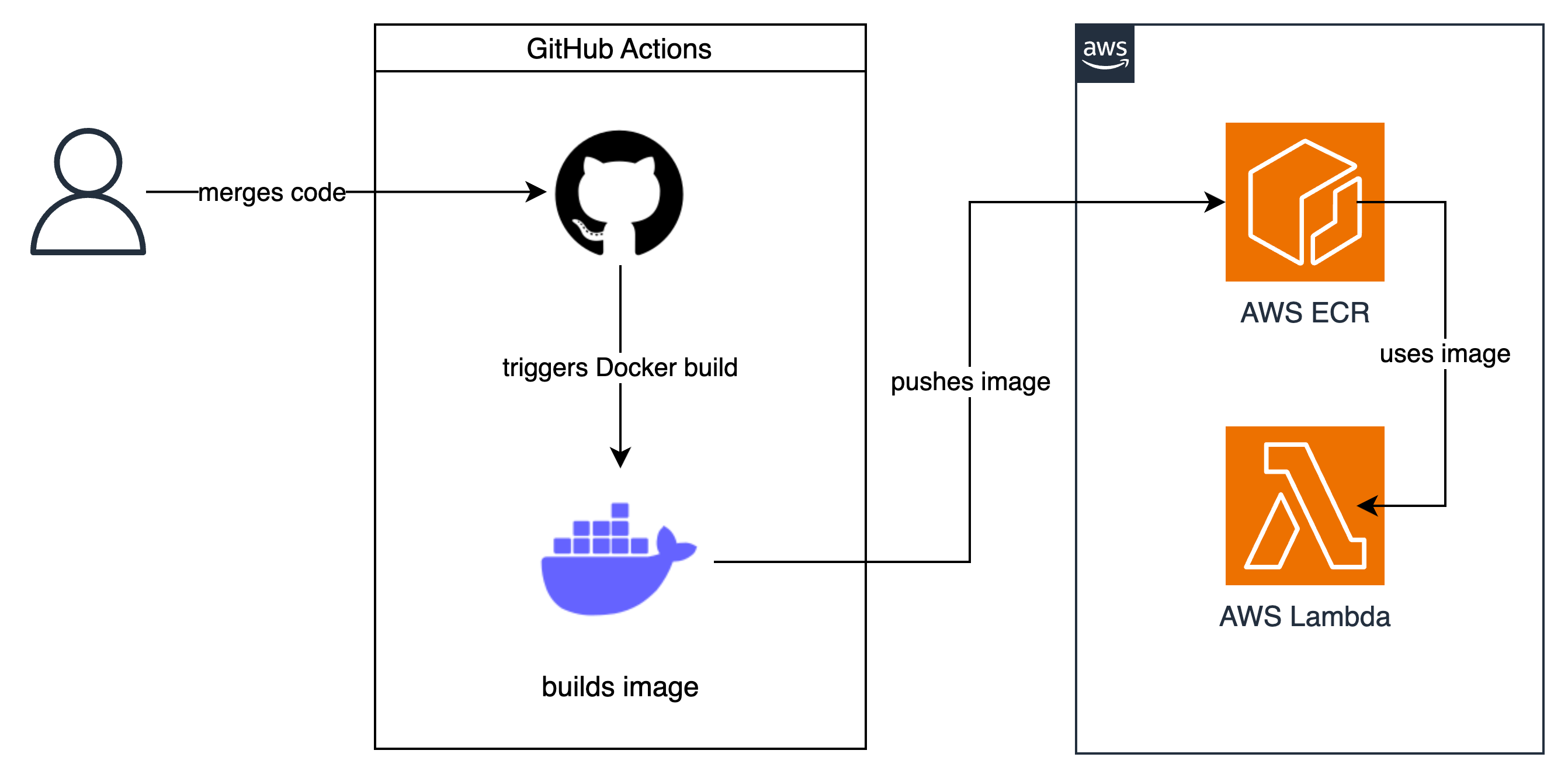
Stack Overview
In an effort to improve our application logging, I merged a small change to our source code. Once the build was complete, my test returned the following error:
"A module that was compiled using NumPy 1.x cannot be run in NumPy 2.0.0 as it may crash."
That’s a weird error I thought, but thank goodness I have version control. I reverted my change, and expected the universe to be right again.
"A module that was compiled using NumPy 1.x cannot be run in NumPy 2.0.0 as it may crash."
How could this still be the error? My requirements.txt doesn’t even have NumPy. NumPy is a sub-dependency of another package…
The Issue
NumPy, the cornerstone library for data scientists and data analysts, has been around since 2008. Almost two decades later, it had its first major release to version 2.0.0 on June 16, 2024. This release has resulted in a number of issues for others.
Comment
byu/commandlineluser from discussion
inPython
After a bit of head-scratching with my team, we discovered that our CI/CD pipeline had automatically updated our application image to NumPy 2.0.0. Unfortunately, as our requirements.txt didn’t explicitly mention NumPy (and the version we used) we couldn’t simply revert our pull request to resolve the problem.
Fortunately for us, we pushed to an image repository that enforced image immutability. This meant that previous versions of our images were kept, so we simply downloaded a previous Docker Image that worked and ran a pip freeze inside it to extract the exact package versions used.
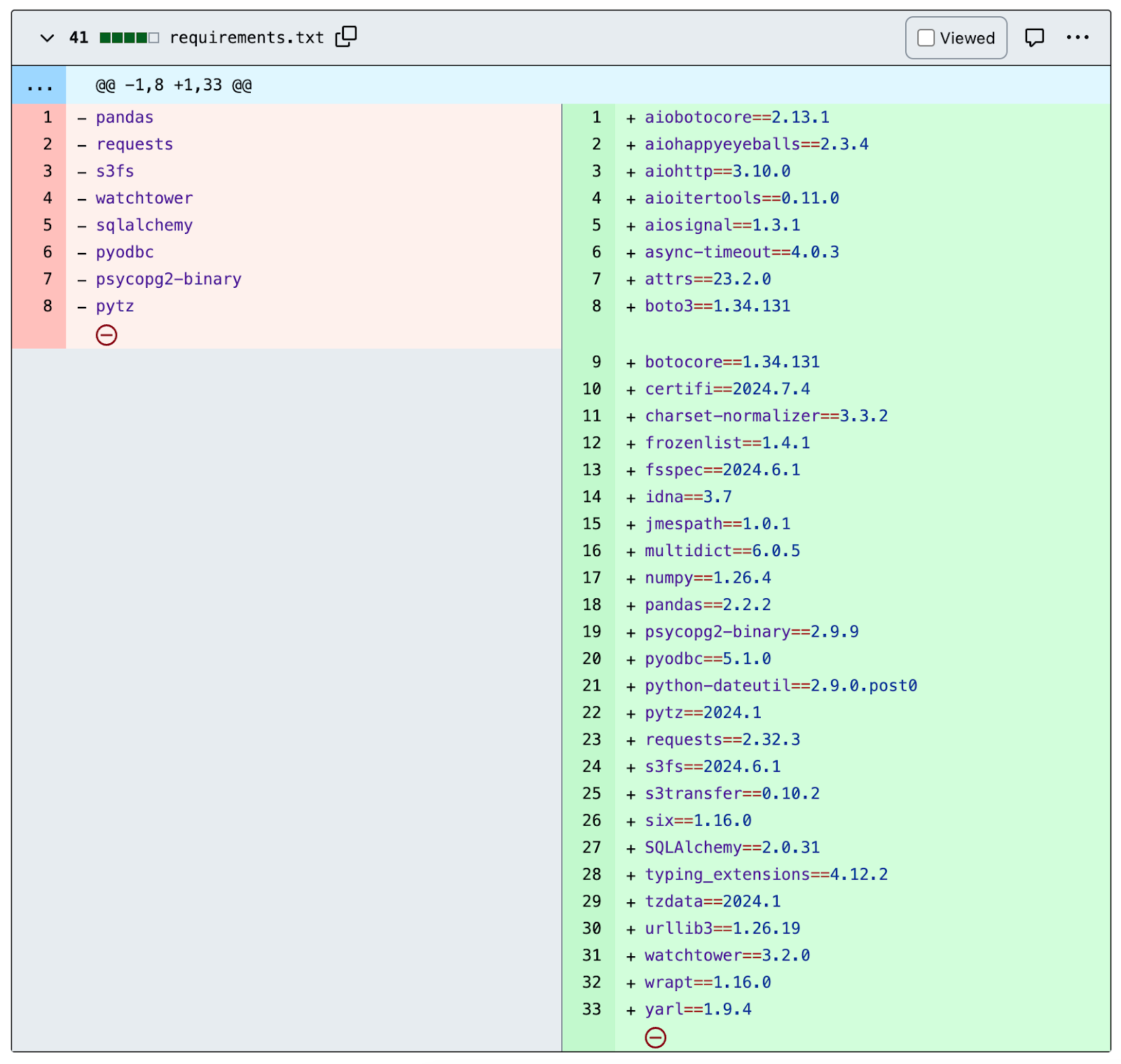
requirements.txt
Key Takeaways
Version Control and Backups: Always keep versions and backups of previous images. Even if the images are created by code, unexpected changes in dependencies can lead to failures. Below is an example of our AWS ECR, and its attached lifecycle policy.
resource "aws_ecr_repository" "this" {
name = local.ecr_repository_name
image_scanning_configuration {
scan_on_push = true
}
image_tag_mutability = "IMMUTABLE"
}
data "aws_ecr_lifecycle_policy_document" "this" {
rule {
priority = 1
description = "Only keep three (3) images for application repositories"
selection {
tag_status = "any"
count_type = "imageCountMoreThan"
count_number = 3
}
action {
type = "expire"
}
}
}
resource "aws_ecr_lifecycle_policy" "this" {
repository = aws_ecr_repository.this.name
policy = data.aws_ecr_lifecycle_policy_document.this.json
}
Freezing Package Requirements: Regularly use pip freeze to capture the exact package versions in use. This practice ensures that your environment remains consistent and prevents unexpected issues due to automatic updates.
+ numpy==1.26.4
- pandas
+ pandas==2.2.2
- requests
+ requests==2.32.3
- s3fs
+ s3fs==2024.6.1
- watchtower
+ watchtower==3.2.0
- sqlalchemy
+ SQLAlchemy==2.0.31
- pyodbc
+ pyodbc==5.1.0
- psycopg2-binary
+ psycopg2-binary==2.9.9
- pytz
+ pytz==2024.1
Comprehensive Snapshots: Using pip freeze provides a complete snapshot of all installed packages and their versions at the time of installation. This snapshot is incredibly valuable for recreating the exact environment later, ensuring consistency across different stages of development and deployment.
Manual Cleanup: Over time, your project might evolve, and certain packages may no longer be needed. However, pip freeze will still list these packages unless manually removed. It’s essential to keep track of your dependencies and clean up the ones you no longer use to avoid unnecessary clutter.
Consider Using pipreqs: For more refined control over your dependencies, consider using pipreqs. This tool generates a requirements.txt file based on your imports, ensuring you only include the necessary packages. It’s a great way to streamline your dependency management and avoid bloating your project with unused libraries.
Wrapping Up
pip freeze is a vital tool for data engineers and analysts. It helps maintain a stable and predictable environment, allowing you to focus on building robust data solutions without worrying about unexpected dependency issues. By adopting good practices, you can ensure that your projects remain consistent, reliable, and easier to manage. So, don’t just burn through your data—freeze your requirements and safeguard your workflows against the chaos of untracked dependencies.
If you’re keen for a chat or have any questions, please reach out to myself or Mechanical Rock.