MLOps Workflow Components
Tags: MLOps Components AWS Machine LearningWhy did MLOps become a thing for ML solutions?
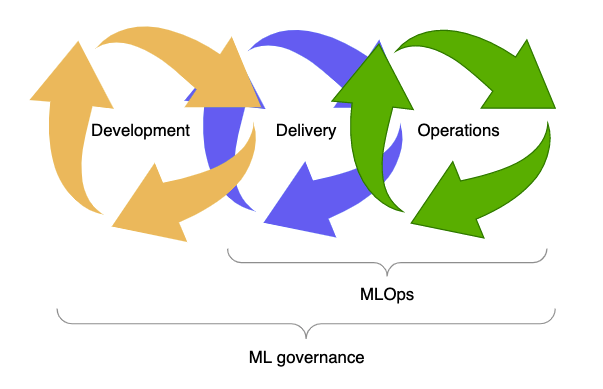
MLOps, short for Machine Learning Operations, involves applying DevOps principles to the lifecycle of a machine learning model. Automation lies at the heart of the DevOps methodology and should also be embraced in MLOps since it is derived from DevOps. The various steps involved in a machine learning workflow, such as model training, tuning, and deployment, are both time-consuming and prone to errors. Without automation, valuable time, effort, and human potential are wasted. Therefore, automating these steps enables data scientists and data engineers to be freed from manual processes, allowing them to focus on developing workflows, differentiating the organization, and expediting the implementation of valuable changes in production.
By adopting Continuous Integration and Continuous Deployment (CI/CD) practices and following good practices, we can mitigate risks in the environment through automated testing and reduce errors caused by manual processes.
MLOps Workflow Components
To gain a comprehensive understanding of the various components within a MLOps workflow, we will begin with the foundational architecture and progressively build upon it to identify distinct stages of the workflow. To implement MLOps, we can identify three levels of automation and incorporate established DevOps practices like monitoring and governance into the process.
Security and Governance
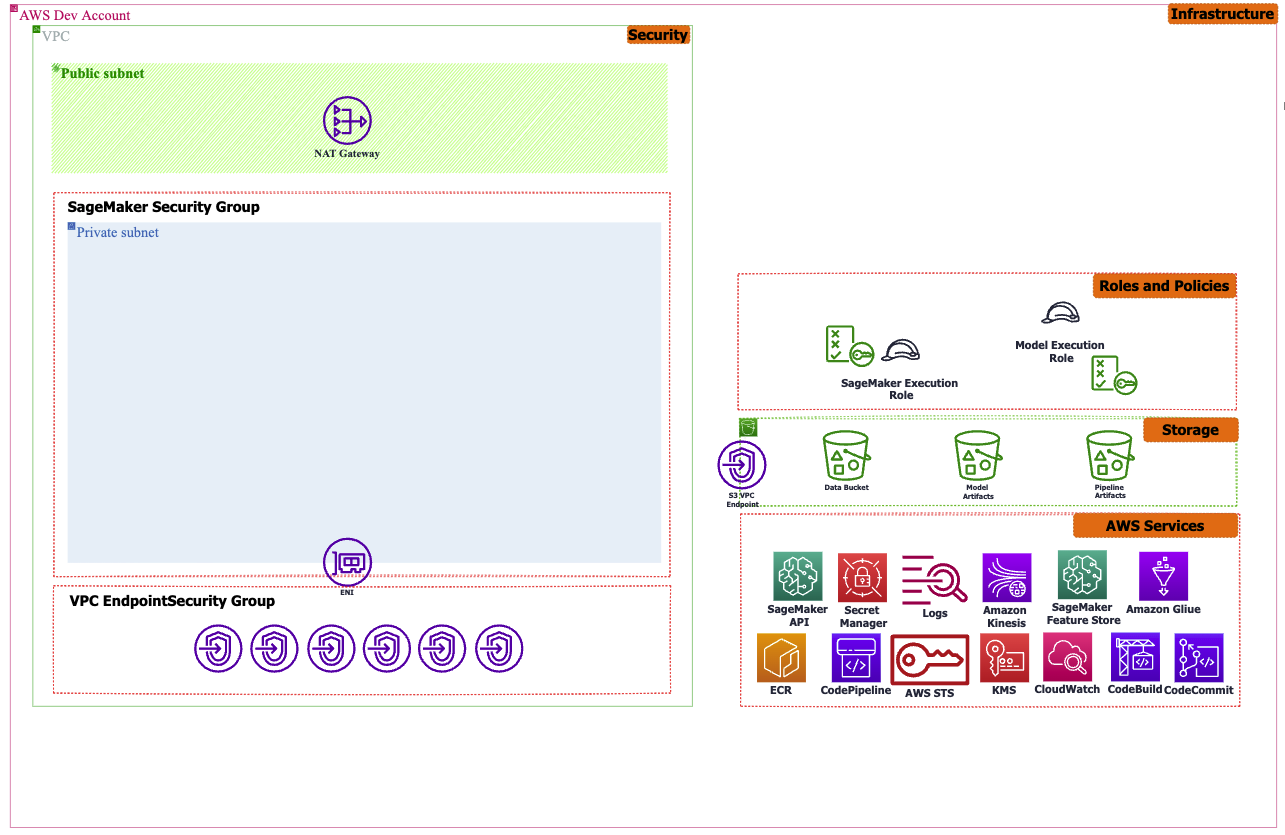
To ensure the security of MLOps solutions, prioritizing security and adhering to recommended security practices at every stage of the ML workflow is crucial. This includes:
- Deploying the solution within a Virtual Private Cloud (VPC) and exclusively utilizing VPC endpoints for AWS services.
- Restricting internet access in ML environments by disabling public network access within resources like SageMaker Notebooks and incorporating Private Subnets and Security Groups.
- Establishing appropriate user and service roles by implementing a least-privilege policy.
- Implementing secure solutions for multi-account architectures, leveraging services such as AWS Control Tower.
- Enforcing end-to-end data encryption during transit and at rest throughout the ML solution.
Monitoring and Continuous Training
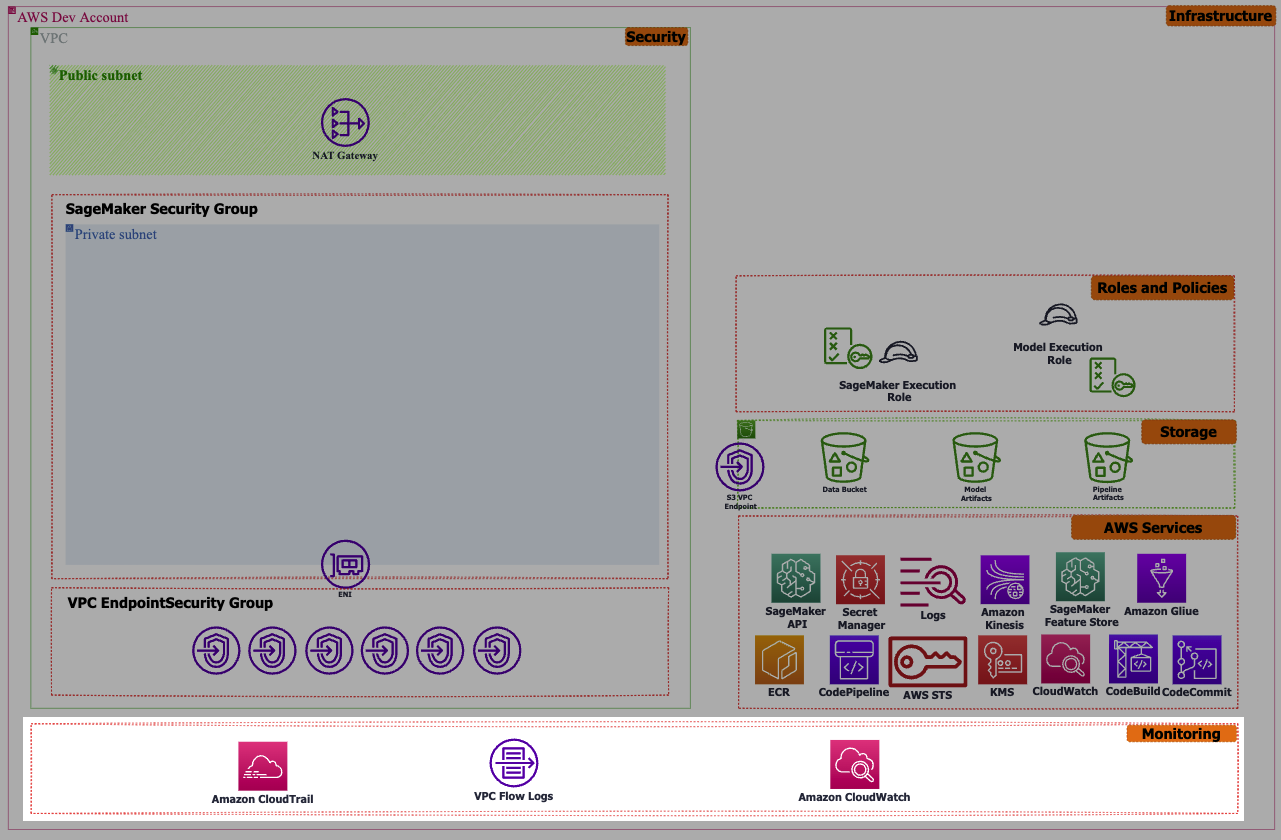
This involves the ongoing monitoring of data and model quality to identify potential bias or drift and promptly address them. An example of this is leveraging Amazon CloudWatch events to automatically monitor drift, initiate re-training, and notify relevant stakeholders in a timely manner.
Exploration
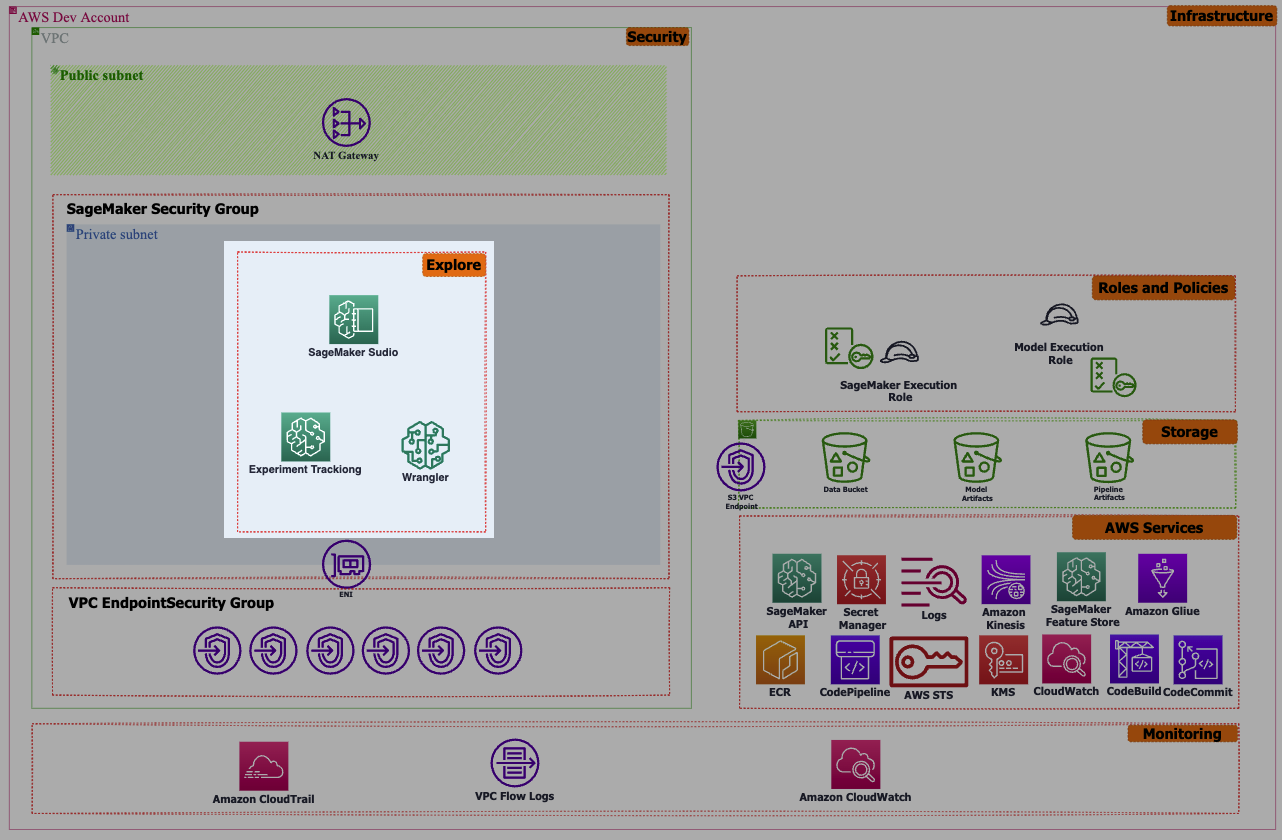
Machine learning operations (MLOps) commence with exploratory data analyzes (EDA), where data scientists analyze a subset of data and employ diverse ML algorithms and techniques to identify the most suitable ML solution. This process is seamlessly facilitated by Amazon SageMaker Studio, offering capabilities for data analyzes, data processing, model training, and deploying models for inference through a non-production endpoint. To ensure the reproducibility of experiments, SageMaker’s Experiment capability tracks all activities performed by data scientists.
ML Pipeline
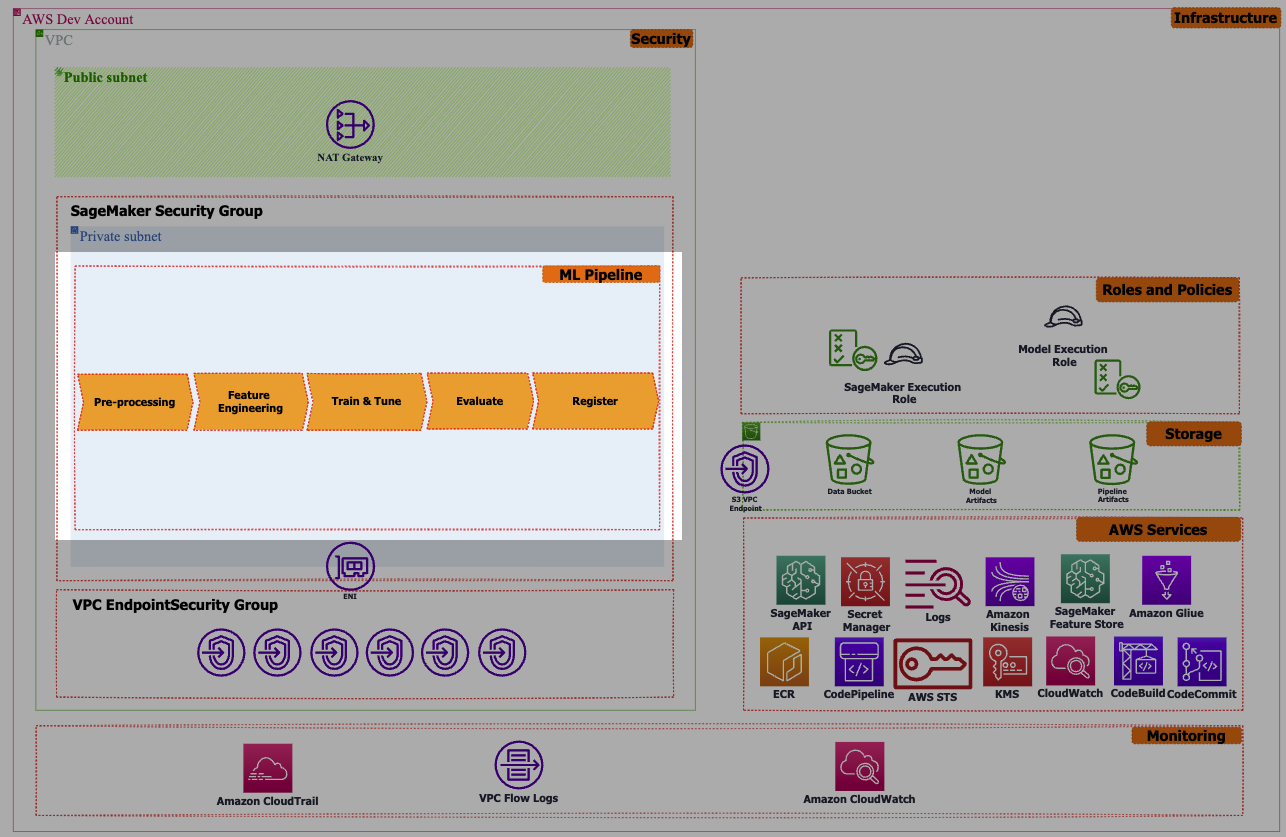
After this exploratory phase, machine learning engineers convert the proposed solution by the data scientist to the production-ready ML code and create end-to-end machine learning workflow including data processing, feature engineering, training, model evaluation, and model creation for deployment using a variety of available hosting options.
Continuous Integration
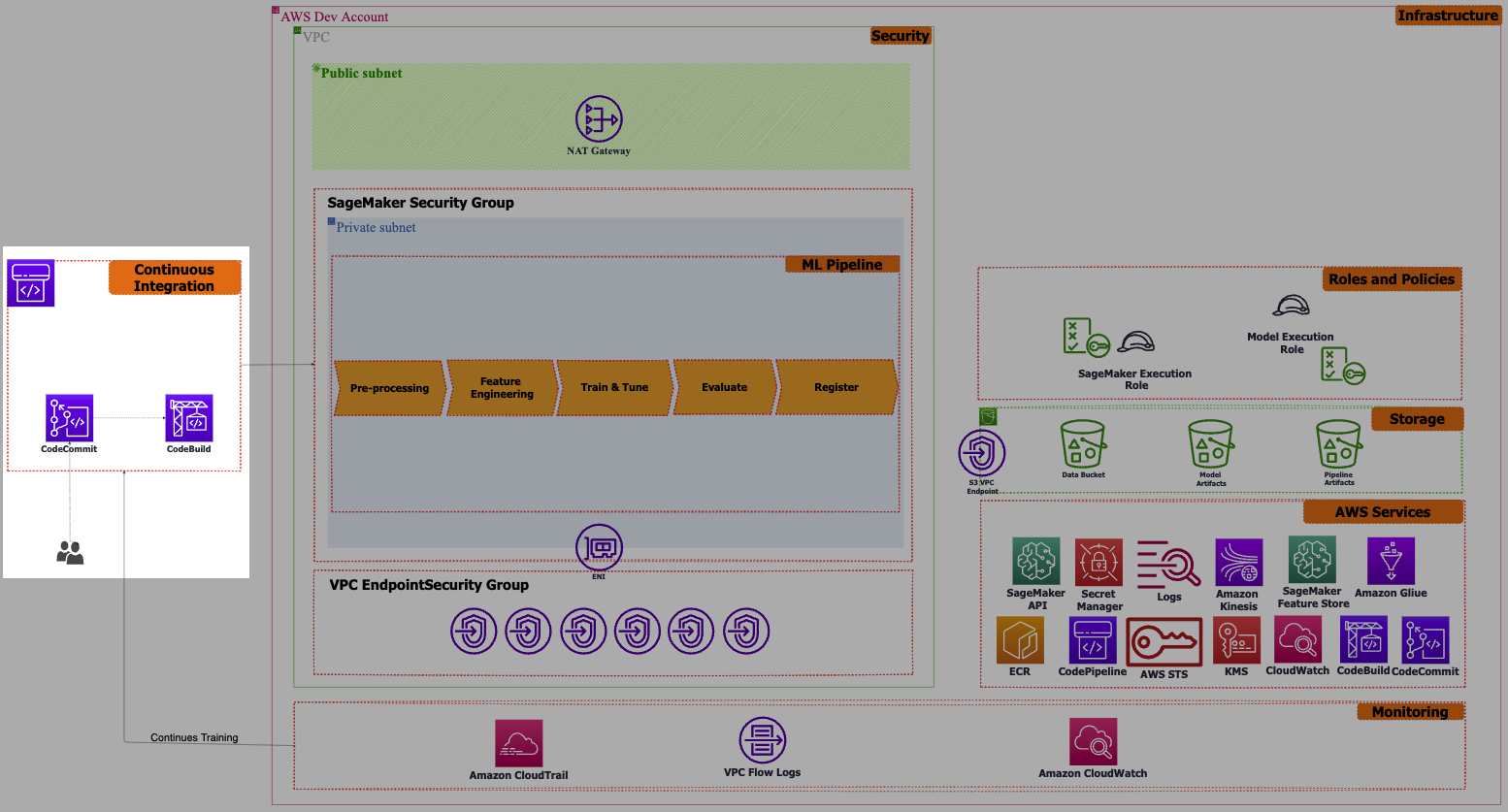
To eliminate manual work as a result of making any update to the code or infrastructure, an MLOps engineer will add the Continuous Integration (CI) capability to the workflow to enable data scientists or ML engineers to regularly merge their changes to ML Code or ML assets/resources.
Continuous Deployment
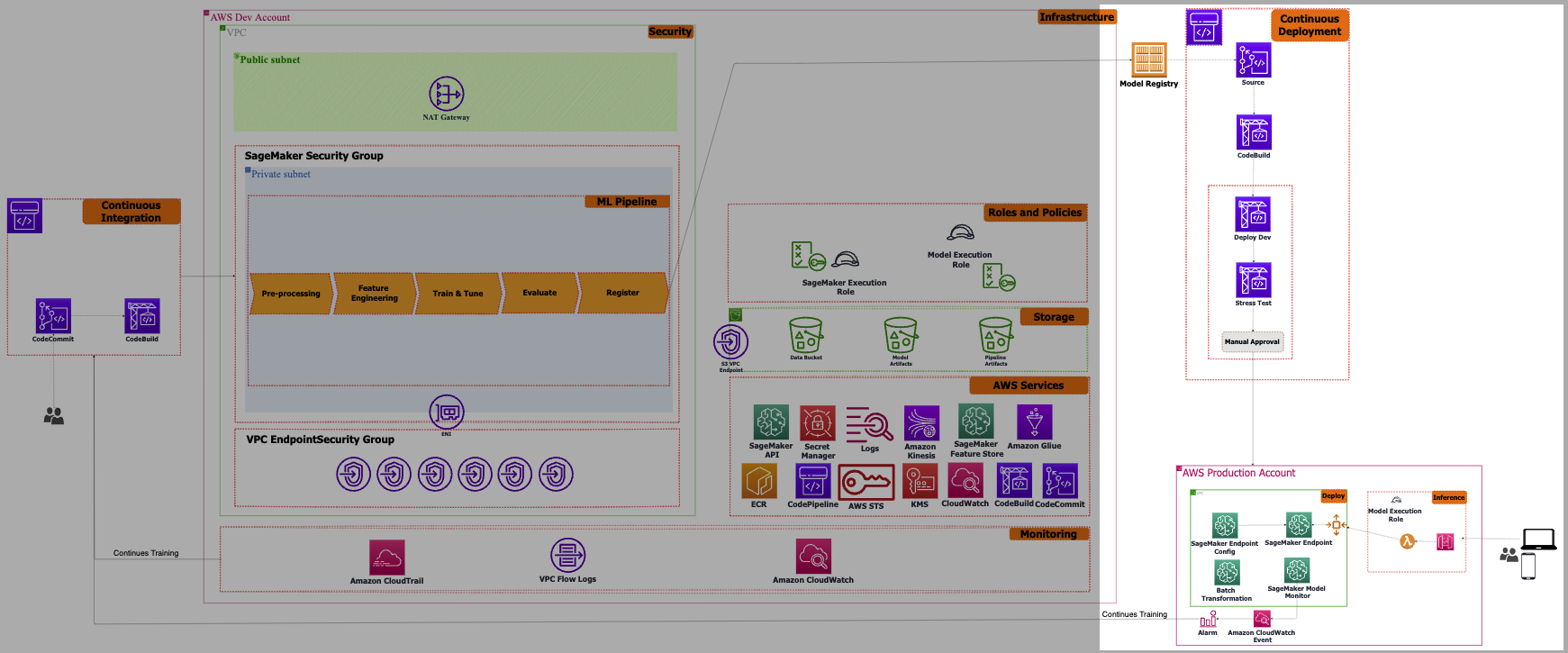
Our objective is to establish not just a continuous building and testing capability but also an automated continuous deployment process to the production environment. To accomplish this, we can separate the training stage of the ML workflow from the model deployment stage. This decoupling enables us to modify the model configuration and infrastructure without impacting the training workflow. Additionally, it provides the flexibility of a rollback option in case any issues arise during the deployment phase.
Final words
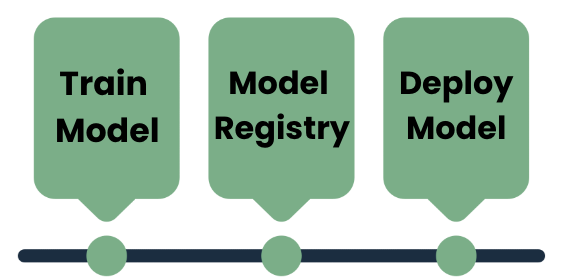
As mentioned in this concise blog post, an ML pipeline typically comprises two workflows positioned on either side of a machine learning model registry. The model registry serves as a centralized hub for managing machine learning models, enabling ML engineers and data scientists to train models, compare different versions, visualize metrics, and make decisions regarding acceptance or rejection. Ideally, approving a new model version initiates a pipeline that culminates in the deployment of the model into production.
In the realm of Machine Learning, particularly within the AWS ecosystem, numerous options exist for crafting an effective workflow. Various services cater to the needs of both Data Scientists, like Amazon SageMaker, and Operations teams, such as Amazon CodePipeline. Familiarizing yourself with the distinctive features of each tool or service empowers you to select the optimal solution for your Machine Learning project and team.
If you’re curious about Mechanical Rock’s approach to architecting Machine Learning solutions or require assistance with your ongoing Data Science project, don’t hesitate to contact us. Our team is dedicated to providing unwavering support and guidance whenever you need it.