Amazon SageMaker Recap, Re:Invent 2022
Tags: re:invent2022 MachineLearning sagemaker aws data dataScience MLOpsWhat’s AWS Re:invent?
AWS Re:Invent is the biggest tech conference and cloud event of the year. A learning conference hosted by AWS where the global cloud community come together to meet, learn and get inspired.
This year for the very first time, I attended the AWS Re:invent conference through the AWS All Builders Welcome grant. As a machine learning enthusiast I participated in a few Chalktalk, workshops in ML/AI learning track and obviously tried to not miss the Re:invent Announcement sessions.
In this blog post, I would like to share highlights of some of the cool stuff that are now available or still in preview for Machine Learning and Data Scientists within AWS AI/ML services and more specifically Amazon SageMaker.
First, let’s look at the end to end workflow of building a Machine Learning solution on AWS and then walk through the new announcements for some of the components in AWS Machine learning architecture.
AWS ML infrastructure and Services
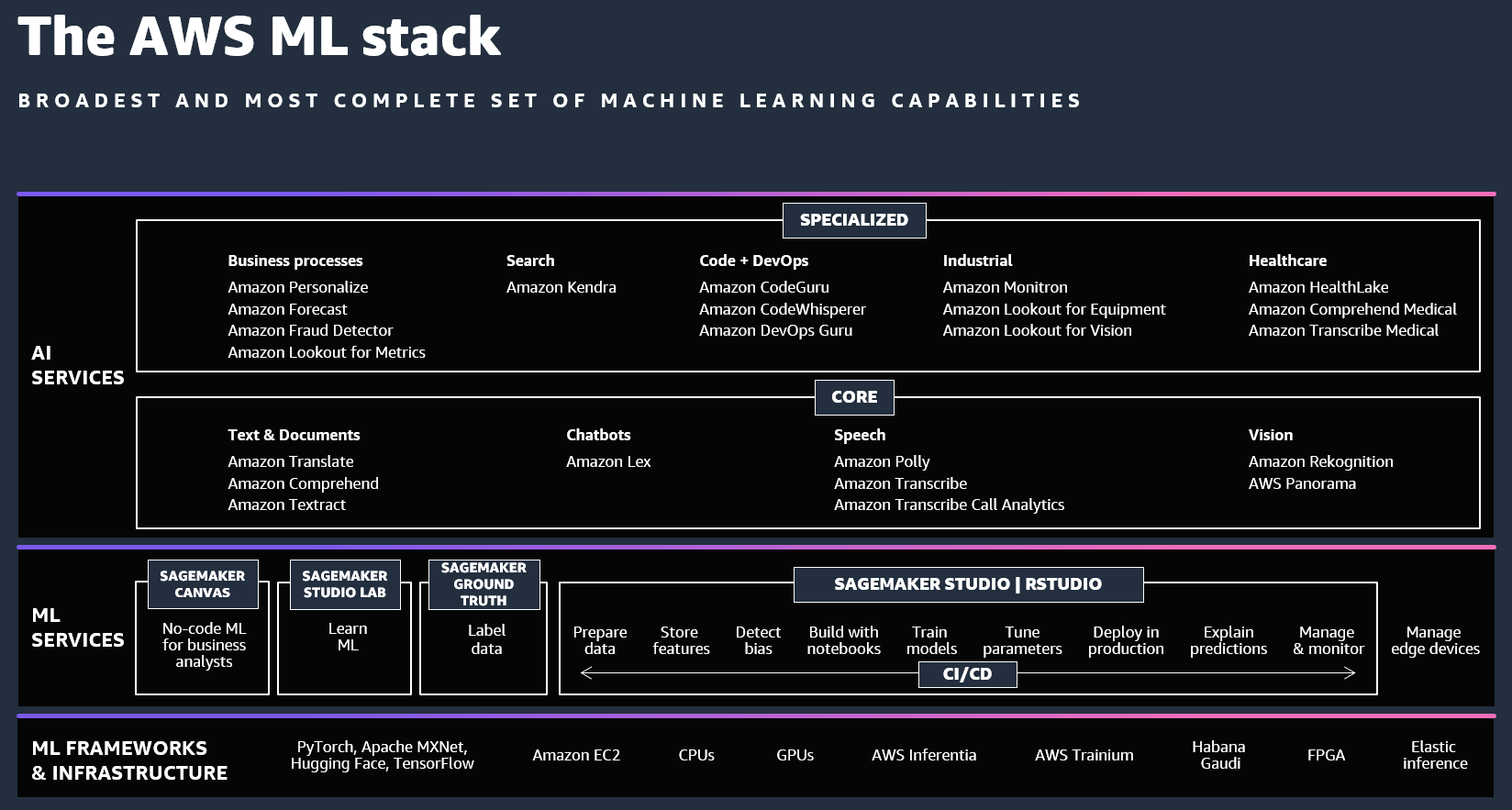
ML Compute
As the graphic illustrates, the bottom layer contains the compute, networking and storage services that construct the foundational block of ML infrastructure on AWS. Here are some recently added capabilities to Compute component in Machine Learning solutions on AWS.
Amazon EC2 inf2 Instances (Preview)
As per AWS documentations, Inf2 instances are powered by up to 12 AWS Inferentia2, the third AWS-designed DL accelerator. Inf2 instances offer 3x higher compute performance, up to 4x higher throughput, and up to 10x lower latency compared to Inf1 instances. The Inf2 instances are designed to deliver higher performance at the lowest cost for Deep Learning inference applications. You can now efficiently deploy a 175B parameter model for inference across multiple accelerators on a single Inf2 instance.
AWS SageMaker Instance (Preview)
SageMaker now supports new instances for training jobs. The “ml.trn1” instances are powered by AWS Trainium chips and are available in two sizes: ml.trn1.2xlarge for experimenting with a single accelerator and training small models cost effectively. ml.trn1.32xlarge for training large-scale models. You can use this instance type on sagemaker to train natural language processing (NLP) and computer vision applications.
AWS SageMaker Inference added 8 new Graviton-based instances (Preview)
The Graviton-based instances are used for Real-time and asynchronous inference model deployment options. Now, ML teams can use Graviton3 instances ml.c7g and Graviton2-based instances such as ml.m6g, ml.m6gd, ml.c6g, ml.c6gd, ml.c6gn, ml.r6g, and ml.r6gd for optimizing their cost and performance when deploying their ML models on SageMaker.
ML governance
Much like software development analogue DevOps, MLOps is also a discipline of Machine Learning lifecycle to deliver models faster by automating the repeatable steps and reduce the time it takes to deploy the model to production. The ML governance on the other hand, is the management, control, visibility, explainability and auditability of the end-to-end ML workflow.
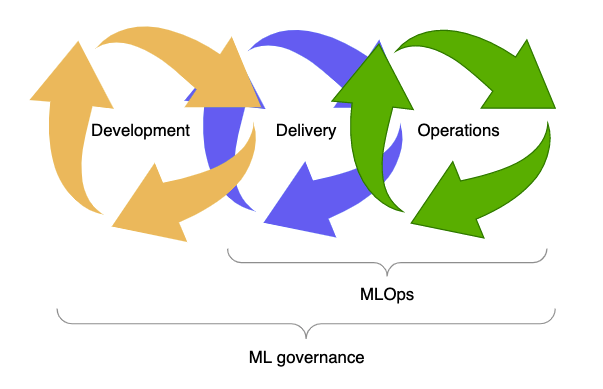
Introducing new governance tools to sagemaker (Available Globally)
Today, Sagemaker as the most popular ML service on AWS offers new capabilities that help us to scale governance across our MLOps workflow.

Amazon SageMaker Role manager:
Allows administrators to control access and define permissions for users within minutes. The SageMaker Role manager provides 3 pre-configured role personas and 12 predefined permissions for most common ML activities. Amazon SageMaker Role manager accelerates the user onboarding by automatically generating a custom policy based on your specific needs.
Amazon SageMaker Model cards:
Amazon SageMaker Model Cards provide a single location to store model information such as input dataset, training environment and training results in the AWS console and streamlining model documentation throughout a model’s lifecycle. You can easily attach and visualize the evaluation result of your model as well as sharing the model cards across your business stakeholders.
Amazon SageMaker Model Dashboard:
As you deploy your model to production, monitoring and keeping the track of your model’s performance is always part of the ML workflow. This task normally gets extremely complex and time consuming when you have multiple models in the operational environment. Amazon SageMaker Model Dashboard provides a comprehensive overview of deployed models and endpoints, enabling you to track resources, model behavior and quality in one place. Once the models are deployed, Amazon SageMaker Model Dashboard gives you unified monitoring across all your models by providing deviations from expected behavior, automated alerts, and troubleshooting to improve model performance.
End-to-end ML solution on AWS
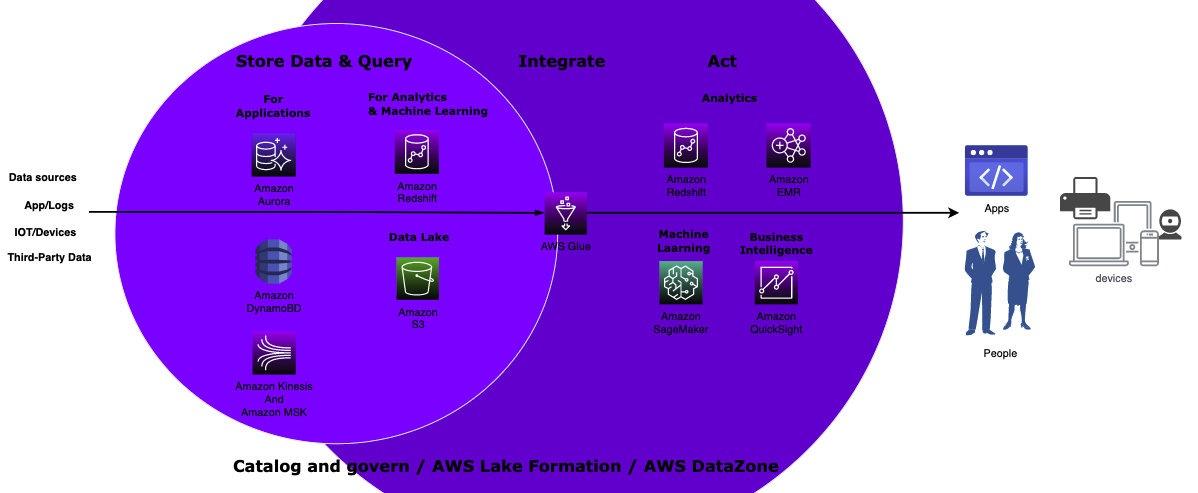
As you know, The end to end workflow of a Machine Learning solution usually consist of the following task:
- Data Acquisition: Explore Data source, extract, pre-process the raw data.
- Data Transformation: Enrich data and convert it into a data format compatible with the input type of your ML training Algorithm.
- Visualization: Visualize the training data for comparison, relationship, distribution and composition analysis on your data.
- Model Training: Train your model with transformed dataset. You can always set Testing metrics to monitor your model during training.
- Evaluation: Evaluate your model with test dataset. AWS SageMaker provides you with evaluating metrics.
- Hyperparameter Tuning: Tune the model hyperparameters to get a better performance and accuracy.
- Production Ready: Deploy your model to inference instances for production use.
We are not going to focus on how design an effective ML flow here, Instead we review what’s new on AWS for each space in the ML solution, such as Data Preparation, Model Training and the inference process on Amazon SageMaker.
Discover, Analyze and Data preparation
Amazon DataZone (Coming soon)

At re:invent 2022, AWS introduced their new data management service that makes it faster and easier to catalog, discover and govern data stored across one AWS account, or on-promise. Amazon DataZone removes the heavy lifting of maintaining a catalog by using machine learning to collect and suggest metadata for each dataset. You can set up your own business data catalog and configure governance policies.
After the catalog is set up, your data consumers can search and discover datasets, examine metadata for context and request access to a dataset.Once they are ready to analyze the data, they can create a “Data Project” which is a shared space where users can pull in different datasets and share access with their team and collaborate on analysis. This service integrates with AWS analytic services such as Amazon Redshift, Amazon Athena, and Amazon QuickSight, which enables your data team to access these services in the context of their data project without any need to manage new login credentials. Hence the data is automatically available in this service.
Amazon SageMaker Data Wrangler new features (Available Globally)
AWS SageMaker Data Wrangler is popular for providing:
- Faster access and query data.
- Data Insights and helping you to understand your data quality.
- Data visualization to identify potential errors or extreme values within your dataset
- Efficient data transformation.
- A model summary, feature summary, and confusion matrix, which help you quickly iterate on your data preparation flows and identify an estimate of the expected predictive power of your data.
Obviously, the process of designing data transformation pipeline is time-consuming and required a cross-team collaboration. The main object of Amazon SageMaker Data Wrangler is to simplify the process of data preparation and all of the necessary steps of data preparation workflow on a single visual interface.
However, You still need to apply all the transformation applied to training dataset for model training to the new data during real-time inference. With new feature announced at re:invent 2022 for Amazon SageMaker Data Wrangler, you can now simply reuse the data transformation flow which you created in SageMaker Data Wrangler as a step in Amazon SageMaker inference pipelines. As a result of that, your production deployment will be speed up.
Amazon Glue for Ray (Preview)
Ray is an open-source compute framework that makes it easy to scale AI and Python workloads, from reinforcement learning to deep learning to tuning, and model serving. AWS Glue is a serverless, scalable data integration service used to discover, prepare, move, and integrate data from multiple sources. AWS Glue for Ray is a new engine option on AWS Glue to process large datasets with Python and popular Python libraries. You can now create and run Ray jobs as AWS Glue ETL(Extract, Transform, Load) jobs. Having said, AWS Glue for Ray jobs can be run on schedule or on demand.
Amazon Athena for Apache Spark (Available Globally)
The Apache Spark allows you to run complex analyses for a variety of size and format of your data. However setting up the infrastructure to run Apache Spark is not easy! With the announcement of Amazon Athena for Apache Spark, you can run Apache Spark workloads, have Jupyter Notebook as an interface to perform your data processing on Athena without the need to provision and maintain resources to run Apache Spark. Considering that Amazon Athena integrated with AWS Glue Data Catalog, This opens possibilities to work with any data source in AWS Glue Data Catalog to analyze and perform multiple calculations and data visualizations using Spark applications without context switching.
Training and deploying models for inferences
Amazon Sagemaker feature store (Available Globally)
In machine learning, the models rely on features to make accurate predictions. Amazon SageMaker Feature Store is a new capability for Amazon SageMaker to store, share and reuse features for real-time and batch machine learning solutions. You definitely know that maintaining consistency between features that were used for model training and at the time of inference is challenging and might result to inaccurate predictions.
Amazon SageMaker Feature Store saves our lives with allowing to reuse the existing features instead of reprocessing features for each new model. With this amazing capability, you can use historical records of feature data and easily reproduce the features as a specific point it time. This will significantly accelerate your machine learning productivity.
Notebook Jobs for Amazon SageMaker studio (Available Globally)
AWS introduced the next generation of SageMaker Notebooks at Re:Invent 2022. As you know, within Amazon SageMaker Studio you can create fully managed Jupyter Notebooks that integrate with tools and ML/Data frameworks to perform all your ML steps from Data preparations, model training to evaluation and model tuning.
Now with the new generation of Amazon SageMaker studio Notebooks:
-
You are able to improve your data quality in a few minutes with new built-in data preparation capabilities. This feature is powered by Amazon SageMaker Data Wrangler to help you understand data distribution and identify data quality issues. Then you receive recommendations for data transformations to resolve the identified issues in your dataset. By applying the recommended transformations, SageMaker Studio notebooks automatically generate the corresponding transformation code in the notebook cells.
-
Collaborate real-time on Notebooks within your team. With SageMaker Studio shared spaces, everyone in your data or ML team can edit, run and access Notebooks. This will accelerate the collaboration and communication during the development process. Also, all your taggable SageMaker resources in automatically tagged in a shared space. As a result of that, you can filter your ML resources as well as monitor cost and plan budgets within your account for your ML workflow.
-
Convert your notebooks automatically to scheduled jobs. This specific one is my favorite capability in the new generation Notebooks. Amazon SageMaker as our one shop Machine learning service allows us to select our Notebook and automate it as a job to run it in a production immediately or on schedule.
Shadow testing for Amazon SageMaker Endpoints (Available Globally)
The common approach to observe performance of variant version of your models is the A/B testing or canary deployment, so that you send a portion of your workload to new version of your model and evaluate the performance and accuracy.
If the performance is accepted then you send all of your workload to the new model endpoint. But now, instead of offline validation with historic data or setting up A/B testing for your new models, you can simply use Amazon SageMaker shadow testing.
Shadow testing helps you build confidence in your model and catch potential configuration errors and performance issues before they impact end users.
Wondering how does it work? through console or API your can create a shadow test for your model then monitor its performance and act on the results. With a few steps, you can select your Amazon SageMaker endpoint and production variant you want to tests against. After configuring the portion of traffic to send to the shadow variance, comparison metrics for evaluation and duration of the test, Amazon SageMaker automatically deploys the new model in shadow mode and routes portion of inference requests to that in real time all on the same endpoint.
Interestingly, only responses from production variant are returned to your application, the logs or responses from your shadow variant on the other hand, can be stored in Amazon S3 Bucket for offline comparison. You can benefit from real-time dashboards in SageMaker Shadow test and finally with configuring your infrastructure, deploy your shadow variant to production.
However, That’s not all. Shadow testing can also be used when you want to apply any changes to your ML components. For instance upgrading to a new framework version, or considering to move to another ML instance type.
Amazon SageMaker JumpStart ML hub (Available Globally)
Amazon SageMaker JumpStart gives access to a wide range of common built-in Machine learning algorithm and pre-trained models to help us with accelerating our ML journey and solving common machine learning problems. The capability of sharing Machine learning artifacts such as models and notebooks within your organization is now available in Amazon SageMaker JumpStart.
If you have multiple data science team who build ML models and Jupyter Notebooks, now you can leverage this new feature and increase productivity and scale your ML solutions within your enterprise. Note that you can add and share ML artifacts developed within SageMaker as well as those developed outside of SageMaker. In addition to that, by enabling training and deployment for your model, you allow users to tune your shared model and deploy the model in just a few clicks through SageMaker JumpStart.
Amazon SageMaker Geospatial ML (Preview)

In the preview, Amazon SageMaker new Geospatial capabilities allow you to easily build, train and deploy the ML model using geospatial data. You can simply bring your geospatial data with a few clicks, prepare it with built-in operations and transformations, build your model with pre-trained deep neural network models and geospatial operators. It also offers, analyze and explore predictions with built-in visualization tools.
If you deal with geospatial dataset and wondering how to use this wonderful capability of Amazon SageMaker, I would recommend you to follow this blog explaining this capability in more details.
Recap of Re:Invent Recap
The innovation in AWS Cloud Services never ends, every year at Re:Invent we get surprised by new announcements. In this article, I mainly focused on compute, data preparation, build, train and deploy on the most popular ML service Amazon SageMaker at a general level. This post was not technical showing how to use the new capabilities, neither covered all the announcements for Machine learning. So if you are interested to know more about what’s been recently announced please make sure to check the AWS announcement platform to read more and in depth about what are the new capabilities or feature for AWS ML services.
More Amazon SageMaker related blog posts coming up. Stay tuned with our future posts If you are keen to learn how to “Tune your model with hyperparameter range” in Amazon SageMaker cost effectively or want to discover “what’s under the hood of AWS DeepRacer” with Amazon SageMaker.
Resources
- https://aws.amazon.com/blogs/machine-learning/celebrate-over-20-years-of-ai-ml-at-innovation-day/
- https://aws.amazon.com/about-aws/whats-new/2022/11/