HVR and HVA for Data Replication
Tags: hvr hva data replicationIntroduction
Recently, several members of the Mechanical Rock team attended a HVR training course in Sydney, hosted by Fivetran. Fivetran is a company that provides connectors to allow synchronisation between source applications and target destinations. In September 2021, Fivetran acquired HVR to make a play on the high-volume database replication space. This blog provides an overview into HVR, and where these tools could potentially be leveraged within your business.
Why HVR/HVA ?
Throughout industry, there is currently a need for faster and high-volume database replication tools, due to the sheer amounts of data being processed/consumed throughout businesses. Fivetran is addressing this need with its recently acquisition of the data replication platform called HVR.
HVR is a high-volume real-time data replication platform that is suitable for a range of data integration scenarios including consolidation of multi-cloud file storage and multi-cloud databases, feeding data lakes, database migration, file storage replication and database replication.
For those who want to rapidly implement replication via HVR, Fivetran offers a managed service (HVA connectors) that reduces setup overhead and ongoing management costs. HVA connectors are a series of connectors that are setup and managed through the Fivetran web dashboard. Currently, there are two commissioned HVA connectors that are ready for use, one uses Oracle as a data source and the other uses SQL server as a data source.
HVR
Change Data Capture
HVR and HVA utilise a log-based Change Data Capture (CDC) method to replicate data between both heterogeneous and homogeneous databases. A log-based capturing method involves maintaining a transaction log that records the content and metadata of a database, in which only incremental changes are replicated from source to target after the initial synchronisation of data. It is worth noting that during the inital load, traditional querying is used. To reduce the initial loads impact on the server, it is recommended to use segmentation and parallel processing if possible. Through utilisation of a log-based CDC method, the following benefits are achieved:
- Low latency
- No requirements required for changes to made either programmatically or to the schema of databases
- Minimal impact to the database itself
These features allow replication to take place between multiple highly distributed systems with impressive speeds (up to 200+ GB per hour), via multiple different replication topologies options.
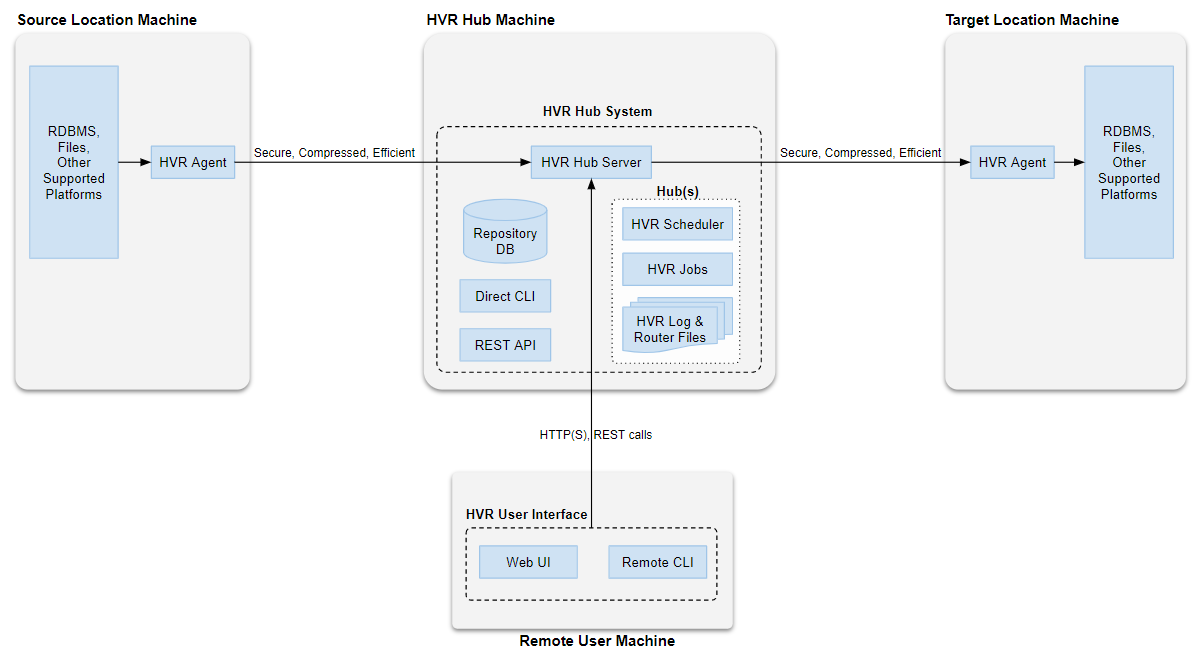
Topologies
There are multiple replication topologies that are supported for use with HVR. The replication topologies include the following:
-
Uni-directional (one-to-one) - Used in scenarios where one would like to offload reporting, feed data into a data lake or to populate data warehouses

-
Broadcast (one-to-many) - Involves one source location and multiple target locations, this topology may be used for cloud solutions targeting both a file based data lake such as S3 as well as a relational database such as Snowflake.
-
Consolidation (many-to-one) - Involves multiple source locations consolidating data into a single target location.
-
Cascading (one-to-one-to-many) - Source location pushing data to a target location that acts as a source location distributing data to multiple targets.
-
Bi-directional (active-active) - Data is replicated in both directions and modified on both sides. It is referred to as an active/active scenario because the two sides are kept in sync. HVR employs the use of collision detection and loop-back detection to protect the integrity of the data.

-
Multi-directional - Multi-directional replication involves more than two locations that are in an active-active replication setup.
Agents, Source Machines and Target Machines
On each source/target machine (database, data warehouse or file) an agent can be installed and configured. The agent performs the capturing/integration of data that is consumed/processed by the HVR Hub Machine. The option to go agentless also exists, in which the HVR Hub Machine accesses a remote database/data warehouse via a DBMS protocol. This is generally not recommended due to the following key benefits provided by utilising the agent:
- Reduction in network costs, distribution of CPU load and capturing of changes direct from DBMS logs
- Compression of data before prior to sending to the hub, resulting in significant bandwidth savings (compression ratio is usually higher than 90%)
- Secure and consistent connections that utilise encryption and authentication
User Interface and Rest API
The two main methods in which a user can interact with the HVR Hub Server are Web UI and Remote CLI. The Web UI provides the means to visualise and control the replication process via a dashboard.
The CLI can be accessed on the hub machine or from a remote machine provided there exists an HVR installation on the remote machine. In addition to the Web UI and CLI there exists a Rest API that can be used to build custom interactions in any programming language.
HVA
Overview
High Volume Agent (HVA) is the marriage of HVR’s replication capabilities with Fivetran’s ease of use. HVR was recently acquired by Fivetran, and in line with Fivetran’s objectives, HVA hopes to house its replication technology within Fivetran’s core product. Presently, HVA is an enterprise ready Fivetran connector for Oracle and MySQL. The throughput of this replication is a staggering 10+ mB/s. The major use case for this tool is for enterprise companies that produce a large amount of data or have large amounts of historical data, that wish to transport its data and leverage one of the many cloud based storage solutions Fivetran integrates with.
Issues solved by HVA
- Massive amounts of data
- High computation cost of replication
- Untimely data access
- Using Oracle
Data collection is ever increasing and enterprises today are racing to leverage it. Replicating operational data in a cloud-based analytical storage solution is one way to do this. HVA is a wicked tool that can do just that… with the right amount of elbow grease.
HVA can handle large volumes of data at a rate of >10 mB/s. Though the initial loading uses a direct SELECT statement to grab the data, continuous replication uses Change Data Capture (CDC). This reduces the data integration latency also known as the load time. HVA implements CDC by making use of the database’s transaction logs. There are ways to alleviate the processing burden placed on the system during initial load. The main method to achieve this is multi-core parallel processing of a pre-segmented table, with each core being allocated a workload.
Finally, you can use this tool to help move away from Oracle to a cloud-based analytical data storage solution. Oracle, though widespread, could be considered overly complex, verbose and cumbersome in its setup, maintenance and use. Cloud-storage solutions such as Snowflake, when leveraged correctly can mean a cheaper and easier to use data solution for many currently using Oracle. HVA can be used to reap these benefits of Snowflake and others by aiding in replicating your data in the cloud. Though if Oracle is serving you and your analytical needs well, then this tool is not for you.
Setup
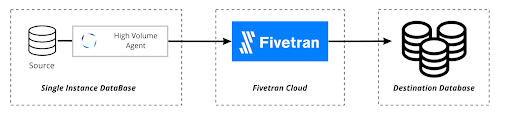
HVA uses an agent-based approach in which an ‘agent’ is installed on the database server. This is due to HVA’s need to read the change data capture transaction logs.
HVA currently supports Generic Oracle and Oracle RAC services. The setup follows these high level steps:
- Choose and configure the type of connection to the source database. These options include:
- Direct
- SSH tunnel
- AWS PrivateLink
- Setup a read-only access User for Fivetran’s agent
- Configure Archive log Mode, Supplemental logging and Configure Direct - Capture to be enabled.
- Install and configure the HVA Agent
- Start the HVA Agent
- Add a new connector in the Fivetran Dashboard
- Specify a destination e.g. Snowflake
A complete setup guide can be found here: https://fivetran.com/docs/databases/oracle/oracle_hva/setup-guide
Though seemingly straight forward, any errors you make will require you to look inward… to search your soul… because the error messages won’t tell you what went wrong.
More often than not, errors from the agent are highly verbose core dumps that are difficult to read rather than actionable debug messages. In addition, though looking fine and dandy from 1000 feet, being in the trenches completing this setup assumes proficiency with SQL databases as well as a general aptitude for network configuration.
During this setup, why you and your data are special will come apparent as some nuances are not obvious. For example, during our setup, the assumption of HVA supporting tables with non-primary keys (the case for our test tables) was challenged. In actuality this support does exist but for only for tables with “non-clob” (non text) columns.
Once the setup is complete, a connector can be added to your Fivetran account via the dashboard.
Fivtran Oracle vs HVA Oracle vs HVR Oracle Example
Every business has its nuances and why they want their data in cloud. For this reason, Fivetran has three options, specifically for Oracle. They are as follows:
| Feature | Fivetran Oracle | HVA Oracle | HVR Oracle |
|---|---|---|---|
| Throughput (database GB/hour) | <10 mB/s | >10 mB/s | >10mB/s |
| CLOB/LOB data types | No | Yes | Yes |
| Interval/Long data Types | No | Yes | Yes |
| Agent Install Required | no | Yes | Yes |
| Log-Based Replication | No | Yes | Yes |
| Log Free Replication | Yes, with teleport | No | No |
| Hosted Hub | No | No | Yes |
| Captures DDL and DML | Yes | Yes | Yes |
| TDE | Yes | Yes | Yes |
| Real Time Replication | No | No | Yes |
| Compare and Repair | No | No | Yes |
HVR/HVA Limitations and Drawbacks
- Initial Setup - Initial setup with both HVR and HVA can be difficult and frustrating at times. The error messages output are often vague and searching the internet rigorously to find a solution will be required, especially if it is the users first time setting up HVR/HVA and they lack database, networking and sysadmin knowledge.
- Security Issues - As much as HVR/HVA are great technologies to plug in and forget, the main issue will be dealing with security teams whom manage the database servers. Having to approach those gatekeepers will likely prove difficult as often they will be adverse to change. Asking them to install an agent on the database server and open various access points will be definitely prove a tough conversation to have.
- Configuration - We here at Mechanical Rock love deploying Infrastructure as Code but unforunately HVA is not configure with Fivetran’s API at this current time. This results in the setup of HVA being a very manual process each time and not easily repeatable.
Conclusion
Within this blog, we have provided a brief overview of HVA/HVR, but the best method of learning new tech is getting down and dirty with it. Provided below are some useful links for getting set up and using HVR and HVA:
If you are looking to setup HVA/HVR in your company, do not hestitate to contact Mechanical Rock!