Data pipelines in Databricks
Tags: Databricks data testingData pipelines in Databricks
Introduction
![]()
I was recently working for a client that required us to create data pipelines in Databricks using software engineering good practices including infrastructure as code, testing and observability. How did we achieve this? In this blog post I will bring you along on our journey of how we were able to implement these data pipelines.
Before I get into the hows I will start with some context around what is a Delta Lake, what is Databricks and how Databricks recommends creating data pipelines according to Delta Lake practices.
Delta Lake
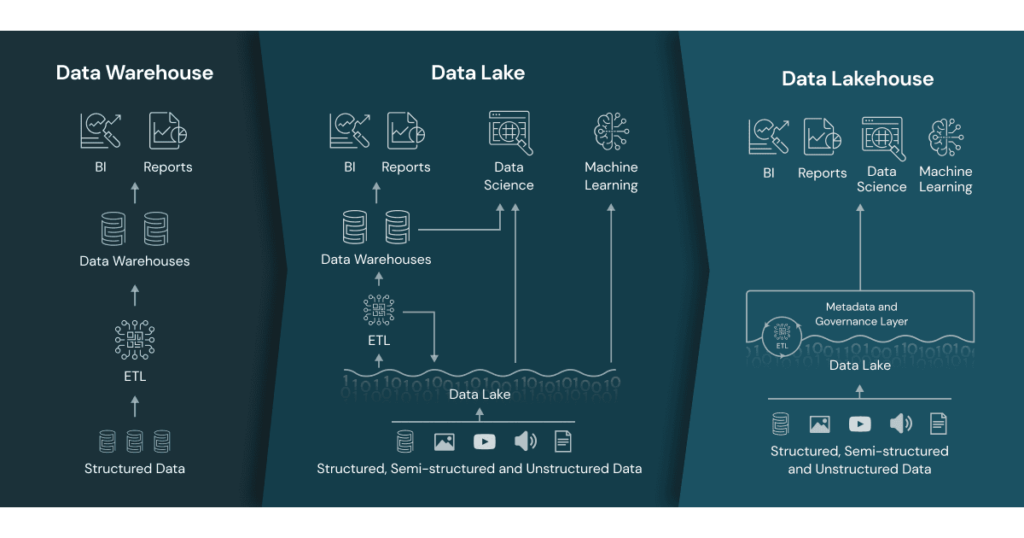
A Delta lake enables developers to create Lakehouse architectures on top of data lakes and is open source. Delta lakehouse combines elements from a data warehouse and a data lake.
Databricks
Databricks provides a solution for ingestion, processing and scheduling allowing developers to run ETL workloads directly on a data lake.
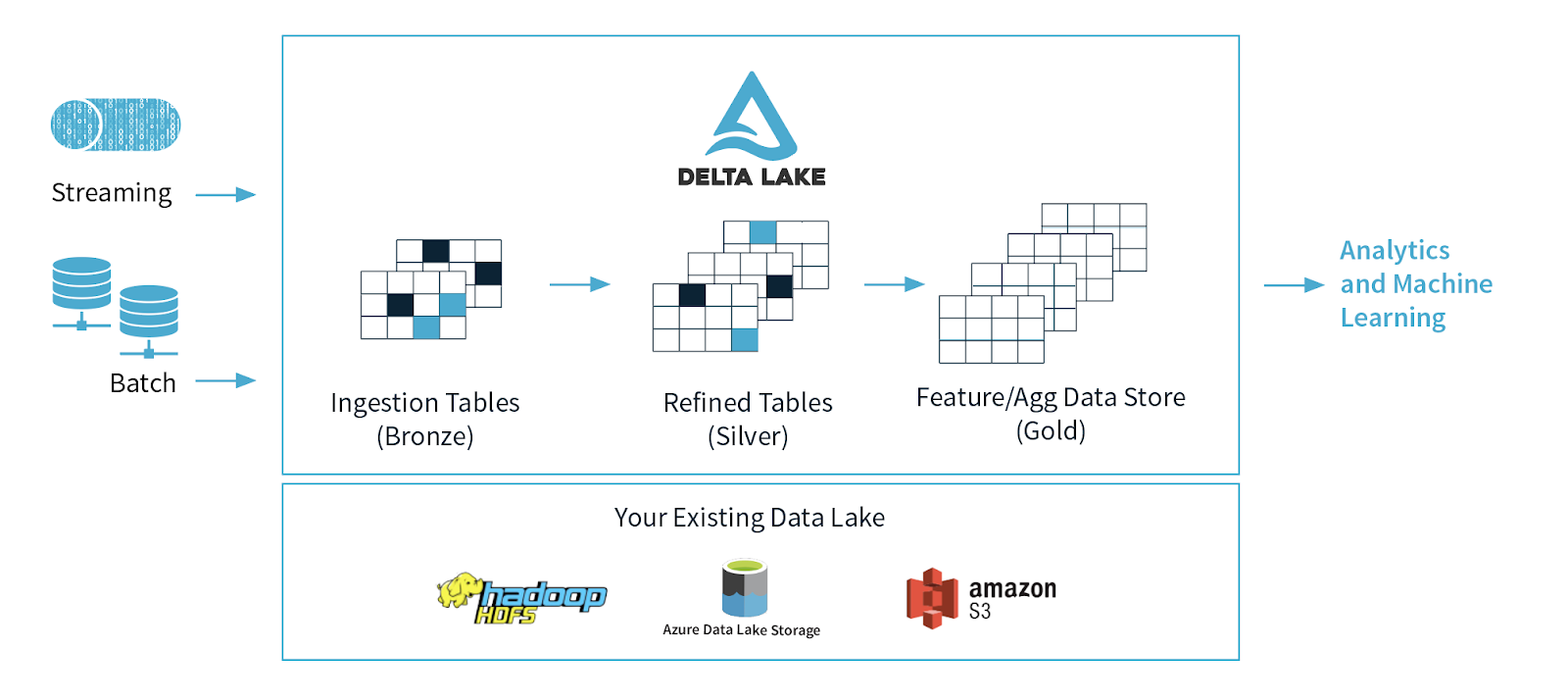
An important part of creating a data solution in Databricks is setting up your data pipeline. A data pipeline in Databricks consist of one or multiple transformation tasks where you transform your data through Raw (Bronze), Cleansed (Silver) and Curated (Gold) layers.
Databricks documentation recommend using Delta Lake patterns for data transformations where you move your data from a Bronze layer to a Gold layer.
- Bronze
- Ingest raw data
- Silver
- Deduplicate data
- Enforce schemas
- Gold
- Perform business-specific transforms to data
- Aggregate data
Multi task jobs v delta live jobs
In Databricks you can use two different methods for creating data pipelines, multi-task jobs or delta live tables. What are the differences and which method did we choose?
Multi-task jobs:
-
This is suited for batch jobs. Multi task jobs need to wait for a task to finish before it can move onto the next task. If you have a streaming job the multi task job cannot determine when to finish a task and move onto the next.
-
Allows you to execute notebooks in a flow
This allows you to set your bronze - silver layer dependencies and run the pipeline in that set sequence. This allows you to have a single workflow or parallel workflows so you can build your data pipeline in a way that suits your individual needs.
Databricks enables you to run your data pipeline on a schedule that is as simple as setting up a cron job in your IaC. The alternative is to go into the Databricks UI and manually trigger your data pipeline.
Delta live tables:
- This is suited for streaming jobs.
- More suited for creating ETL pipelines.
Although delta live would have been better suited for our needs we did not use delta live as it was still in preview and not ready for production workflows at the time.
How to
Below I will go through some of the tooling we used and how you can get started yourself in a few easy steps.
This example will be using Terraform.
You will need:
- A file to declare your notebook definitions
- A file to declare your pipeline
Notebook Definitions
A notebook definition file is where you declare your notebook resources, this can be your Databricks notebook or an s3 bucket.
resource "databricks_notebook" "my-notebook"{
path = "The absolute path of the notebook"
source = "Path to notebook in source code format on local filesystem"
language = "PYTHON"
}
Pipeline Declaration
Below is a basic example of where to start when creating your data pipeline using multi-task jobs. The key thing to note is that you can have multiple tasks and tasks can depend on other tasks.
resource "databricks_job" "my pipeline" {
name = "my-pipeline-name"
schedule {
quartz_cron_expression = "my-cron-schedule"
timezone_id = "Java-timezone-id"
}
task {
task_key = "task_1"
notebook_task {
notebook_path = databricks_notebook.path
}
}
task {
task_key = "task_2"
depends_on {
task_key= "task_1"
}
notebook_task {
notebook_path = databricks_notebook.path
base_parameters = {
*
variables used in notebook e.g.
env = "DEV"
table = "my-test-table"
*
}
}
}
}
How might this look?
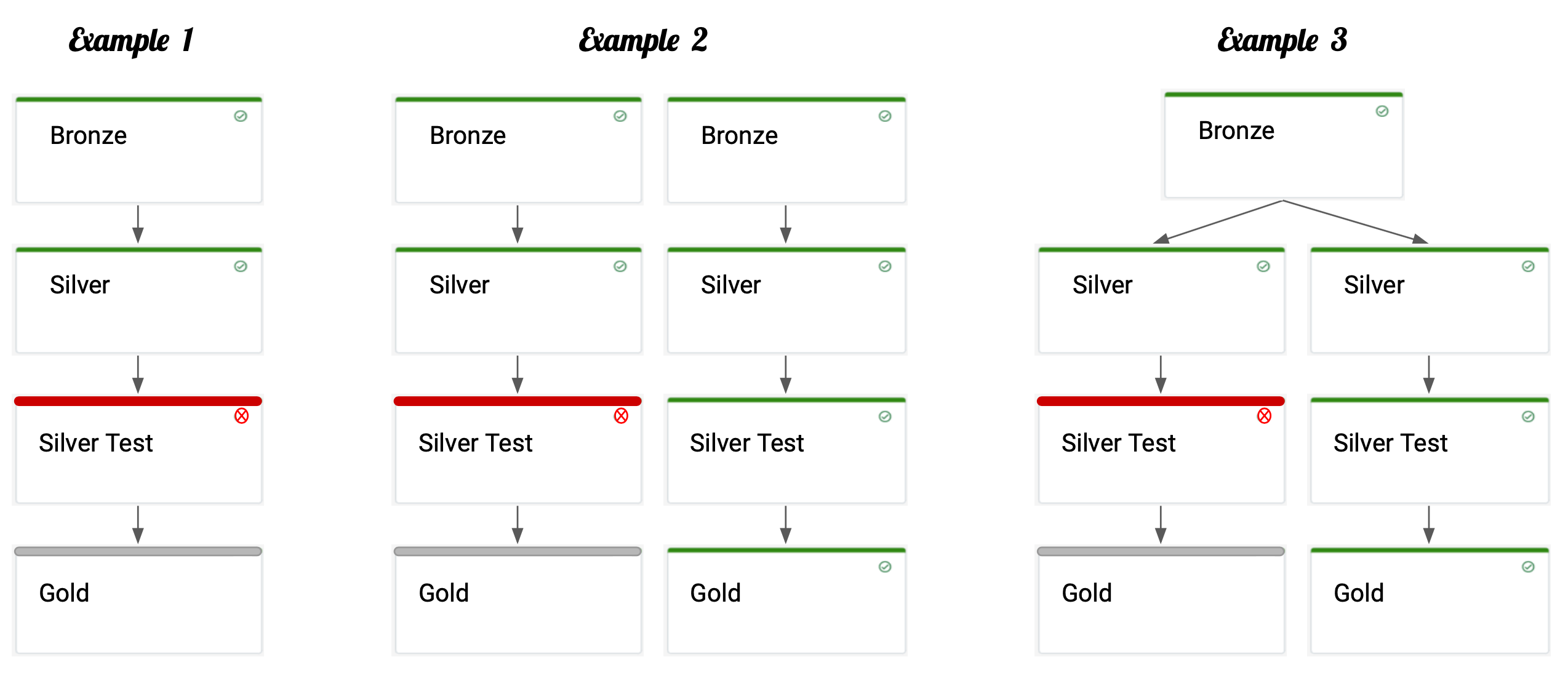
Testing
Tests can be incorporated into the data pipeline, this enables you to fail the pipeline if any of your tests fail. This allows you to have greater confidence in your data, if your silver tests fail then your gold table will not be generated with bad data.
Once you identify a broken test you can then go in and fix any issues and re-start the pipeline.
Great expectations
One of the testing tools we used with Databricks is great expectations for data quality testing and this can be incorporated directly into the data pipeline.
This allowed us to test for some of the following:
- Define what columns we expect to see in the table.
my_test_table.expect_table_columns_to_match_set(columns_set=['col_1', 'col_2', 'col_3'],exact_match=True, result_format='COMPLETE')
- Define any specific values we expect a column to contain.
my_test_table.expect_column_values_to_be_in_set(column = 'col_1', value_set=['Rottweiler', 'Jack Russell', 'Pomeranian','Husky'],result_format='COMPLETE')
- Define any columns that should not contain null values.
my_test_table.expect_column_values_to_not_be_null(column = 'col_2')
- Define any columns that should contain a unique value.
my_test_table.expect_column_values_to_be_unique(column = 'col_3')
More about great expectations test suite can be found here.
Alerts
There is no point in having a pipeline running in the background and never knowing if the pipeline has failed. Luckily Databricks has some inbuilt features you can leverage to alert your development team when things are going wrong.
Databricks enables you to send pipeline failure notifications to an email list and you can set up your email to send notifications to slack.
Challenges
Some of the challenges we faced were:
When you create a multi task job in Databricks, dags are auto generated. This was a challenge because as we created more tasks and more tasks dependencies, the pipeline would start looking very messy and dependency arrows were colliding into each other. There is no flexibility to move the dags around or to adjust how they are generated
We were unable to run streaming jobs in multi task jobs due to the pipeline not having any context as to when the streaming job would be completed. This is a constraint of using multi task jobs.
There is no way to define dependencies between jobs. When you have multiple pipelines you can’t specify dependencies between them. For example my stage two pipeline cannot run once my stage one pipeline completes because you can’t define the dependency between the two pipelines.
Wrapping up
For this client we were able to set up a data pipeline which had a clear RBAC model, testing and alerting. There will always be more you want to add or optimize, one of the things we started looking into was setting up Prometheus for monitoring and observability.
Setting up a data pipeline is only the first step, you want to build it once and build it right.
If you think we can help you set up your data pipeline the right way, feel free to contact-us.