It's a Bird.. It's a Plane… No! It’s Supercompute in the Cloud!
Tags: cloud hpc supercompute lustre aws batch
What is Supercompute aka High Performance Computing (HPC)?
HPC, which is also commonly referred to as Supercompute, is a computing platform that aggregates multiple computers into one “Supercomputer”, just like the Voltron Lions join together to make one big robot to achieve greater power and performance in order get the job done quicker, or in Voltrons case; destroy the enemy in a more efficient and effective manner. HPC technology will help accelerate the processing of your compute intensive workloads, jobs that would normally take days or weeks to complete on a standard single computer can be completed within minutes or hours on a Supercomputer.
In fact, Woodside have just announced that they have been successful in simultaneously using more than 1 million virtual Central Processing Units (vCPUs) on Amazon Web Services (AWS) infrastructure to run a Full-Waveform Inversion Seismic Data Processing job which would normally take 2 weeks, was completed in under 2 hours! You can read more about it on their Media Release
With a large number of computers aggregated into the one supercomputer, we can also parallelise the processing so large problems can be divided into smaller ones, which can then be computed and solved at the same time.
These supercomputers are generally used to solve complex problems in the research, science and engineering space to:
- Process large amounts of data for further intperpretation and analysis
- Train AI models
- Perform complex molecular simulations
- Predict the weather forecast
- Quantum Physics
- and much more
Just like you need a professional race car driver to drive a formula 1 car to its maximum potential, you ideally need users of supercomputers to be experts or specialists in their field who also understand what makes HPC technology fly.
With the public cloud vendors starting to offer more HPC services as a fully managed service, it has lowered the barrier of entry for many researchers, engineers and scientists to get a slice of the cloud computing capacity. We are now finally starting to see HPC tooling in the cloud mature to help ease the process of migrating HPC workloads into the cloud. More researchers and scientists are now realising that the public cloud is an enabler for them to help utilise vast amounts of compute power without the monumental task of building an energy efficient datacentre with hardware capable of running their workloads and having the resources to maintain it. The costs to do it in cloud becomes more of an operational expenditure and we get the elasticity to scale up and back down to practically zero in some cases; you don’t use it, you don’t pay.
Lets now see how we can run a HPC workload in AWS, the Cloud Native DevOps way.
As an example we will use LAMMPS(Large-scale Atomic/Molecular Massively Parallel Simulator) which is a Classical molecular dynamics application that can model Atomic, Polymeric, Biological, Metallic, Granular, and coarse grained systems.
Molecular dynamics (MD) simulation is becoming an invaluable tool for studying biomolecular structure and dynamics, for instance; we can use LAMMPS to compute the viscosity of fluid using 6 different methods.
So lets start by first Containerising the LAMMPS application with Docker or Singularity which will also make it easier to shift your workloads between environments, eg Hybrid Cloud. Here is a sample Dockerfile to build your LAMMPS Container image which can then be published to the aws container registry ECR. This image will be a little overweight. OpenMPI is also included in this bundle so please trim to your specific needs
FROM ubuntu:20.04
RUN apt-get update
ENV DEBIAN_FRONTEND=noninteractive
RUN mkdir /scratch && useradd -d /scratch hpc-runner -s /bin/bash
RUN chown -R hpc-runner /scratch
RUN apt-get install -y software-properties-common vim
RUN add-apt-repository -y ppa:gladky-anton/lammps
RUN add-apt-repository -y ppa:openkim/latest
RUN apt-get update
RUN apt-get install -y lammps-stable
USER hpc-runner
CMD lmp_stable
Then you must profile your application:
- Is it IO bound
- CPU bound
- Memory Bound
- Interconnect/Networking bound (Eg: Use of Message Passing Interface)
- Can computing nodes be distributed across availability zones(physical datacentres)
Knowing where your application spends most of its time along its HPC journey will go a long way in helping you run cost efficient and performant HPC jobs.. You get this wrong, and it could empty your wallet and waste a lot of your research time.
Here are some performance and benchmark profiling results from the HPC-AI Advisory Council for our LAMMPS application.
CPU Scaling Profile
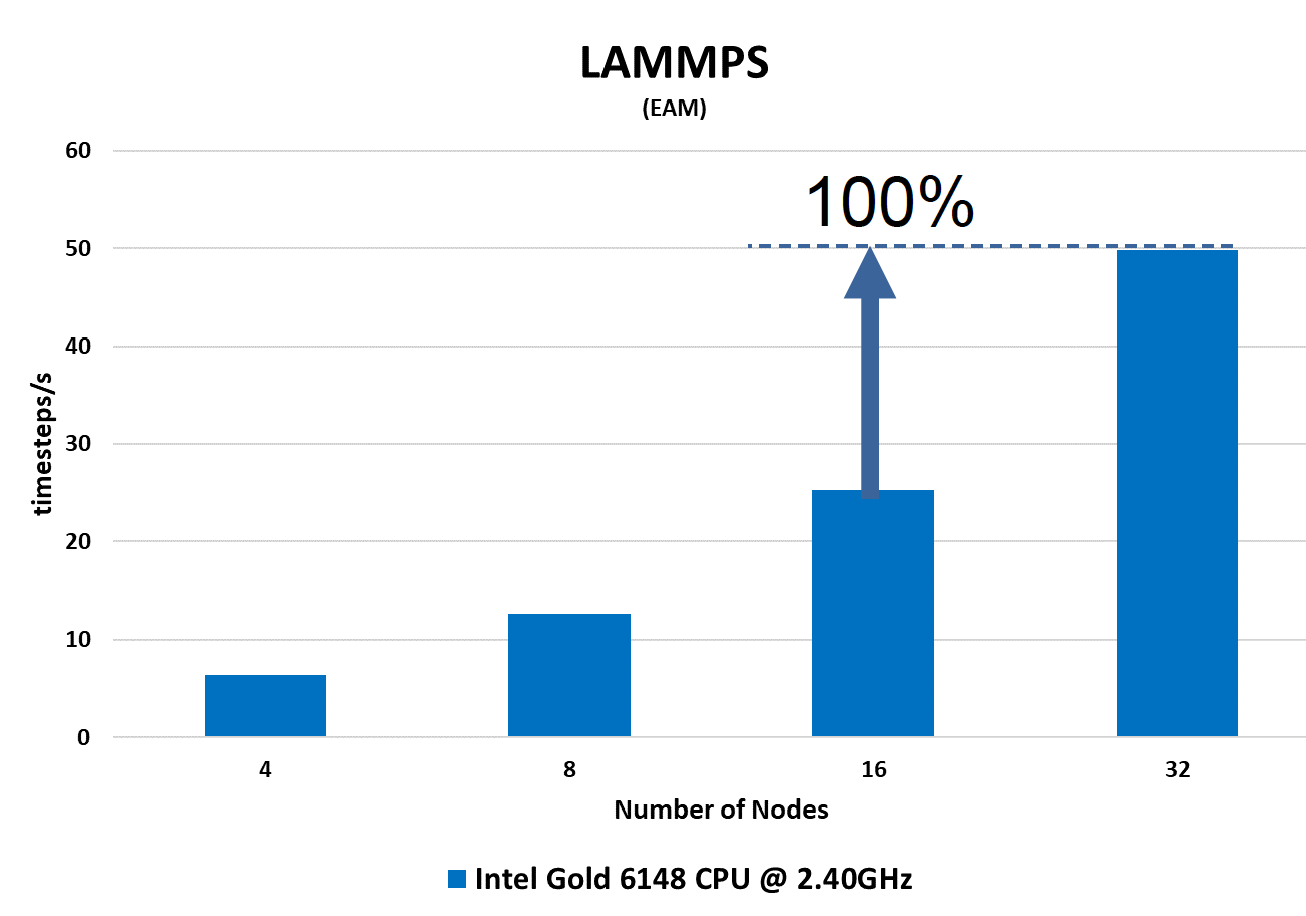
LAMMPS Performance comparison between 2.40Ghz and 2.50Ghz CPU

LAMMPS MPI (Message Passing Interface) Profile

For our case we now know LAMMPS runs efficiently in parallel using the message passing interface, which means inter-node(computer) communications bandwidth will play a key part in how the simulation job performs. Extra CPU cycles will also help accelerate performance. We are not IO bound as we are not dealing with large datasets.
We then build an AWS HPC environment the DevOps way, using Cloudformation Infrastructure as Code in a CI/CD pipeline. The LAMMPS workload above will be based on the following architecture:
AWS Architecture
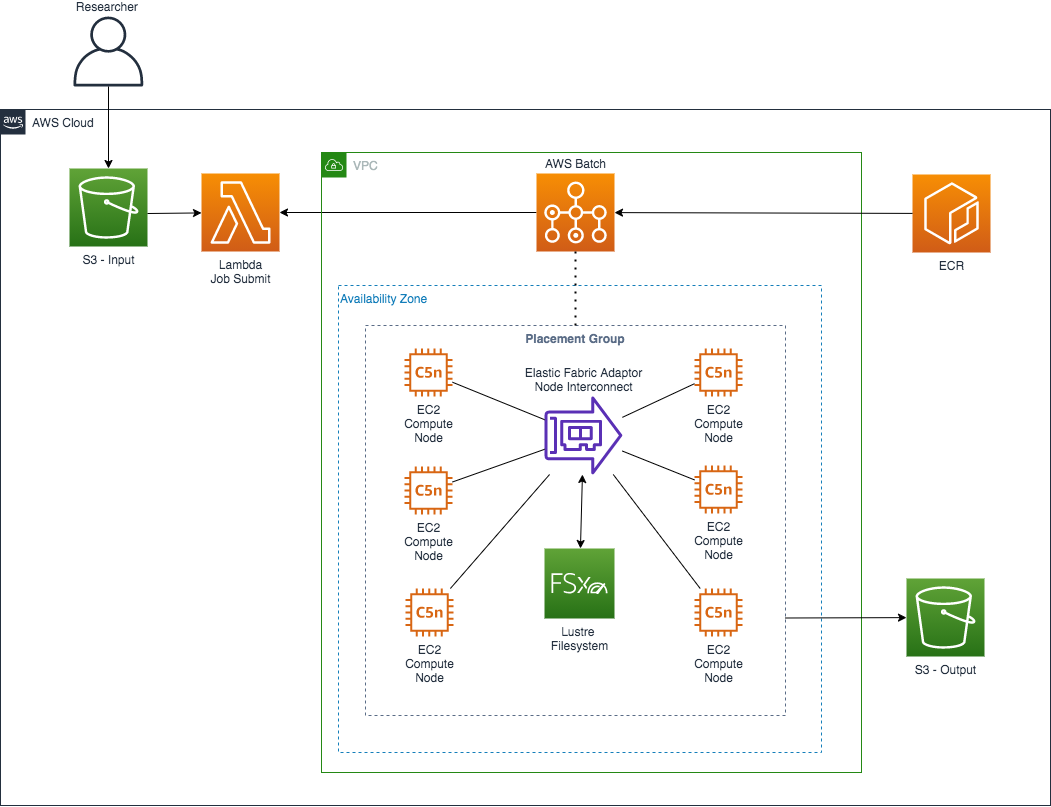
The above architecture will use AWS Batch as the core scheduler and workload manager for the HPC jobs submitted by the triggered Lambda. AWS Batch is a cloud-native batch scheduler for HPC, ML, and other asynchronous workloads. AWS Batch will automatically and dynamically size instances to job resource requirements, and use existing FSx for Lustre file systems when launching instances and running jobs. Lustre is a Parallel Filesystem which excels in most HPC environments, you can find out more about Lustre Parallel Filesystem Here
The LAMMPS HPC workflow would run as follows:
- Researcher uploads LAMMPS input and Job parameter config files into an s3 input bucket
- This s3 upload will trigger a Lambda that will take the Job definition parameters and Submit the job to an AWS Batch Queue.
- AWS Batch will pull down the LAMMPS docker image from ECR and deploy it to the EC2 SPOT instances that will run the job in multi-node parallel mode.
- AWS Batch will launch the job on EC2 SPOT Instances which have EFA(Elastic Fabric adaptor) available for high bandwidth interconnect to help keep the MPI_Wait times down.
- AWS Batch will also create the compute cluster within 1 Placement group in Cluster strategy mode, meaning that all compute nodes will be within the 1 availability zone/datacentre, keeping latency between nodes low to also help keep MPI_WAIT times low.
- AWS Batch will also mount the /scratch filesystem(Fsx Lustre) onto the compute nodes for you.
With Fsx for Lustre we get the option to deploy it as a “scratch” deployment type which is ideal for temporary storage and shorter-term processing of data. The output file can be written to Fsx for Lustre and then with some AWS Magic, we are also able to read the same file from an S3 bucket that is linked to the Fsx Lustre Filesystem. Researcher then retrieves the output from the S3 bucket.
So there you have an example on how to run a compute intensive hpc workload in cloud, easy enough right?
But what if we have huge amounts of data.. Petabytes of Data or more?
Lets take for example Seismic Data or even what the SKA Square Kilometre Array project will potentially generate. The challenge comes when you try to move such large volumes of data around.. It can get expensive and complicated very quickly. If you try to manage this data in an on-premise datacentre, you would ideally need a Hierarchical Storage Management (HSM) solution to help automate the lifecycle of your big data and integration with your application. Your data would live in the ONLINE Storage Tier (high performance storage) when it’s needed for processing. After processing has completed, the data can then be migrated to a NEARLINE Storage Tier (low cost storage) and then if long term Archiving of the data is needed, it would be migrated to the OFFLINE/TAPE Storage Tier.
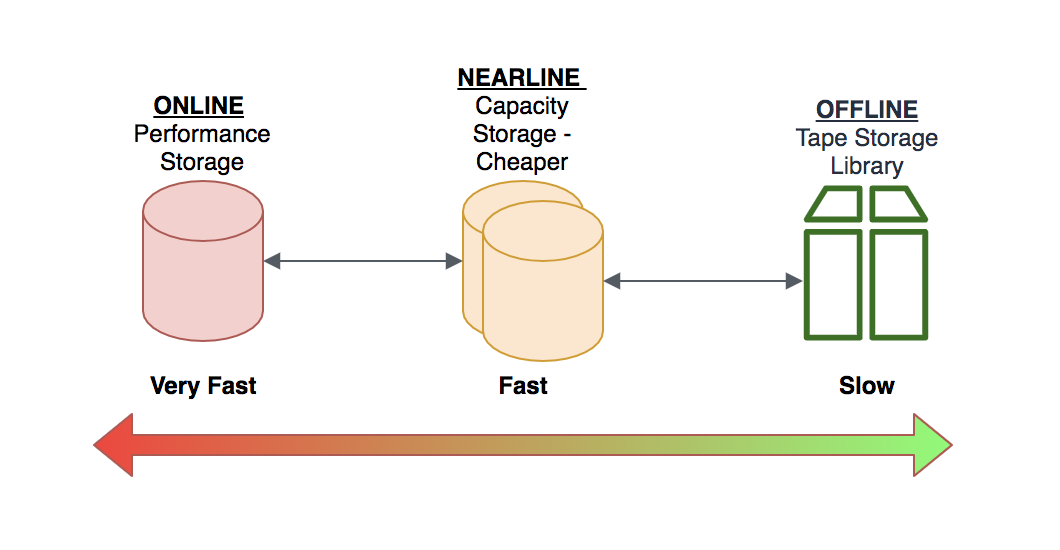
Do you really want to maintain such a system yourself? AWS have solved this problem by having FSx for Lustre integrate natively with Amazon S3, making it easy to access your S3 data to run data processing workloads. FSx for Lustre transparently presents S3 objects as files and allows you to write results back to S3, which also means we now have access to a tiered storage solution with S3 lifecycle policies! Voila! Brilliant work AWS! Coming from a background where maintaining Lustre and HSM solutions for on-premise HPC is a 24x7 job equating to a high TCO, This is a huge win in my books… Just a word of caution though.. Yes you now have automated your data management strategy with most of the responsibility shifting to AWS, but as we are now migrating your data to a cheaper storage tier in the cloud, please DO your homework and math on the costs to retrieve the data from the archive storage tiers along with potential egress charges. You have been warned $$$
Another way to help reduce the volume of data being migrated to the cloud is to have a pre-processing step at the Edge - Hybrid Cloud or Edge Computing, which is when Kubernetes can be a good option to consider as it can cater for a wide variety of use cases. This will help reduce your data footprint in the cloud, where you only transfer the pre-processed(cleansed, filtered, noise reduction) data for the core computational workloads in cloud rather than “all” the raw data. You can have the raw data written to tape or disk for archiving in a secure vault somewhere.
Cloud Supercomputing - Fighting the good fight!
Supercomputing cloud platforms have come a long way in helping make available the technology to a wider audience who are looking to process large volumes of data, model complex simulations, weather forecasting or even to help accelerate the search for corona virus treatments and vaccines which will help us understand the nature of the virus and to potentially model the spread of the outbreak. On the flip side to that, with the global use and the rapid technological advancement of Supercomputing technology, experts and world leaders are starting to get nervous about the future of global security if it’s not regulated properly. So let’s focus on fighting the good fight! If you are interested in learning more about HPC/Supercompute in the cloud, I would love to chat with you over a few beers or coffee! Or If you are ready to shift your HPC workloads to the cloud and need some guidance, get in touch with us at Mechanical Rock