Sharing data effectively in a cloud native data lake
Tags: aws cloudformation lakeformation glue data
Introduction
If you’re building a data platform for your organisation, you may be wondering how to make data in one business area accessible to other areas. You want the technology to support the way your organisation works and enable you to scale without creating headaches.
For example, let’s say you’re building a dashboard as part of a solution for a customer. The dashboard aggregates data from stores belonging to other departments.
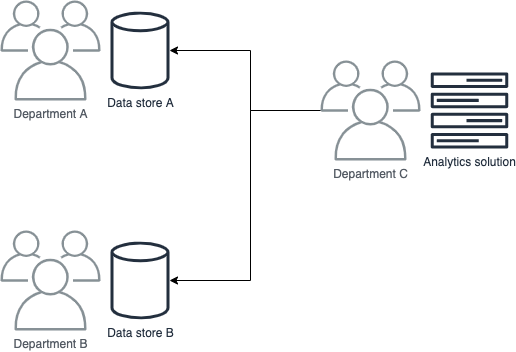
How can we solve this problem for a data platform built on AWS? These data stores are in completely different AWS accounts belonging to different teams. How do we know what data is available in each of those stores? What is the schema of the data? How can we get access to it?
If these sound like problems that are relevant to you, then please keep reading! We’ll go through the steps of building a cross-account resource sharing solution with AWS Lake Formation.
Which AWS services can help?
One service that can help is AWS Glue, a managed service that enables crawling of data repositories to help assemble a data catalog. Glue also provides tools for Extract, Transform and Load (ETL), called Jobs.
But, one of the challenges with AWS Glue is sharing resources across AWS accounts. You can share access in Glue using role-based access control with IAM roles and policies, however this requires knowledge of the underlying storage mechanism (i.e. the S3 bucket name and path). You also need to create policies on both the Glue Catalog and S3 Bucket.
In our scenario, the consumer wants access to a given table in the source catalog and is not concerned with the details of storage. This is where AWS Lake Formation can step in. AWS Lake Formation is another managed service that builds upon the capabilities of AWS Glue. It streamlines access management and eases cross-account sharing of resources.
Lake Formation provides a simple granting mechanism that will be familiar to SQL experts. The target of these grants can be IAM identities, or it can be an AWS account or an entire AWS Organisation or OU.
After creating a grant, Lake Formation integrates with AWS Resource Access Manager to create a cross-account resource share. Lake Formation administrators in the target account will then see the shared catalog resources in their local data catalog.
Scenario overview
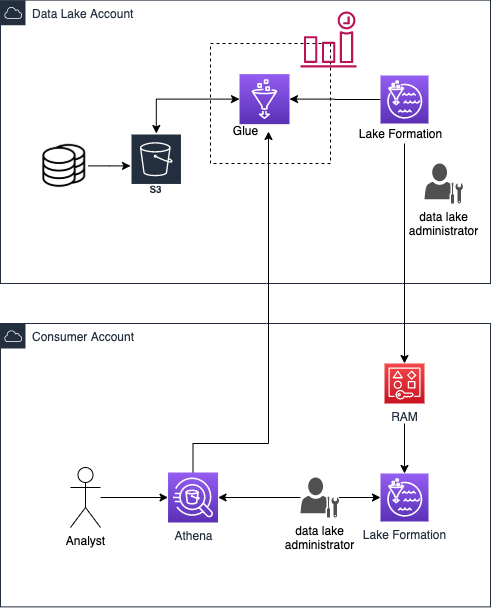
Our goal is to share data across AWS accounts to enable a multi-source data analytics solution. Now that we have an idea of what services can be useful, let’s start to think about what our end to end technical solution looks like.
The source accounts will need:
- Somewhere to store their data – We can store CSV files in an S3 Bucket
- A way to catalog that data, so that the data is visible and schema is known – We can use a Glue Crawler to create tables in the Glue Catalog
- A way to share that data to other AWS accounts – AWS Lake Formation grants, as we covered in the previous section
The consuming account will need:
- A way to query the data in the source account – AWS Athena queries on the AWS Lake Formation resource links to the source account.
The diagram below demonstrates how those components can work together for this solution:
Setting up Lake Formation
To start with Lake Formation you will need to first assign a Lake Formation Administrator. The administrator will then be able to manage access to resources in the data catalog within the same account and across accounts.
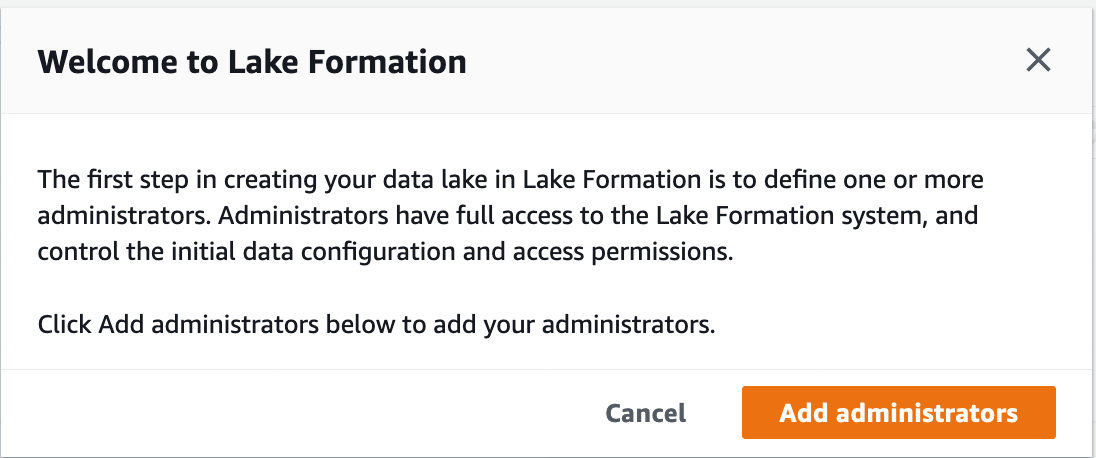
The Lake Formation administrator can either be an IAM user or IAM role. To Setup an IAM role as the administrator, you will need to deploy below CloudFormation code:
AWSTemplateFormatVersion: '2010-09-09'
Description: My data lake source
Resources:
LakeformationSettings:
Type: AWS::LakeFormation::DataLakeSettings
Properties:
Admins:
- DataLakePrincipalIdentifier: arn:aws:iam::100000123000:role/aws-reserved/sso.amazonaws.com/AWSReservedSSO_AWSAdministratorAccess_56cabj890003333
To deploy the above CloudFormation stack, store the template in the file datalake.yml locally and run the following command:
aws cloudformation create-stack --stack-name my-source-glue-stack --template-body file://datalake.yml --capabilities "CAPABILITY_NAMED_IAM"
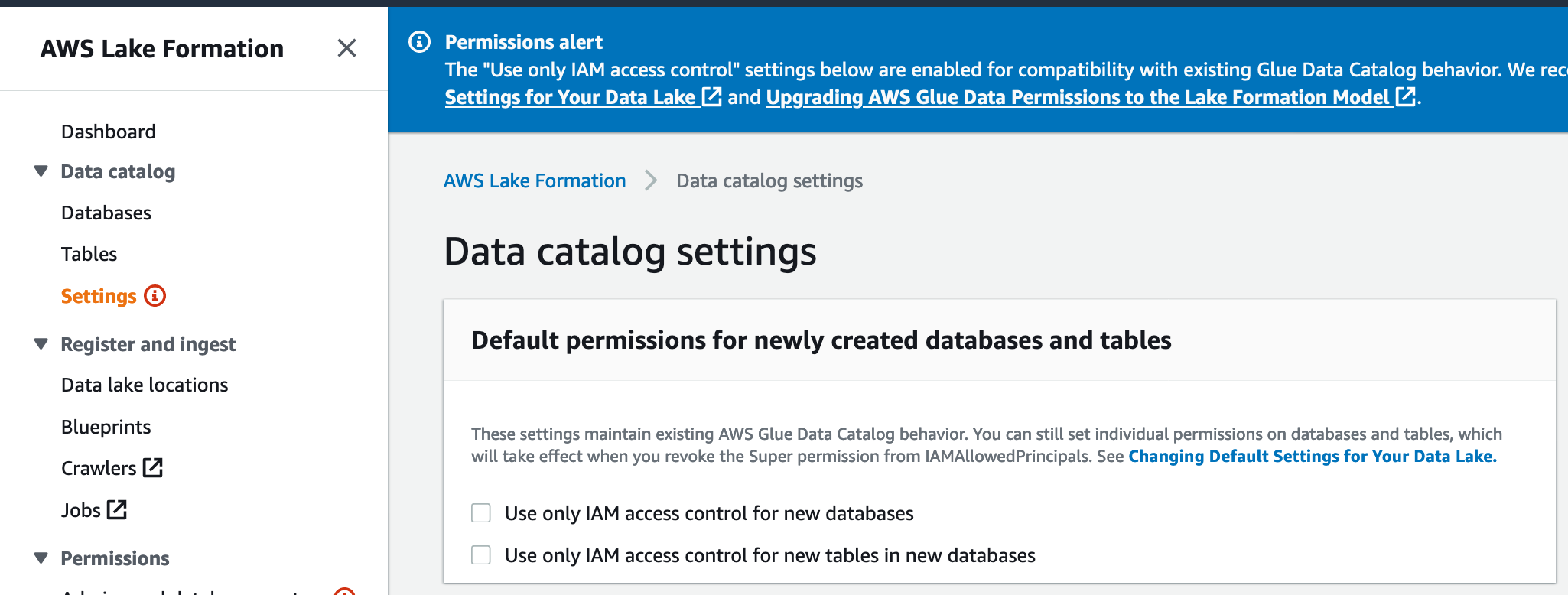
The second step in setting up lake formation is to change the Lake Formation permission model from IAM to Lake Formation native grants. Unfortunately, this setup is not available via CloudFormation at this time, so we’ll need to make the change in the AWS console.
To enable Lake Formation Permissions, go to settings, untick both “Use only IAM access control for new databases” and “Use only IAM access control for new tables” and press save.
Establish our source lake
In this blog post we are focusing on the cross-account sharing of Lake Formation, therefore the assumption is you have already ingested your data from the source into an S3 bucket.
Our starting point will be our source bucket and a Glue database for putting our catalog objects into. The following CloudFormation snippet will create those resources:
MySourceDataStore:
Type: AWS::S3::Bucket
DeletionPolicy: Delete
Properties:
AccessControl: Private
BucketName: !Sub 'my-source-data-store-${AWS::Region}-${AWS::AccountId}'
BucketEncryption:
ServerSideEncryptionConfiguration:
- ServerSideEncryptionByDefault:
SSEAlgorithm: AES256
MySourceGlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: my-source-glue-database
Description: String
Add the above code in your datalake.yml and run the update command below:
aws cloudformation update-stack --stack-name my-source-glue-stack --template-body file://datalake.yml --capabilities "CAPABILITY_NAMED_IAM"
Let’s copy over some data into the bucket. To do that, download the CSV file below and upload it into your bucket.
You can upload the file using AWS CLI or from the S3 console:
aws s3 sync . s3://my-source-bucket
Now, let’s add the crawler and give it permission to read the bucket and write to the catalog:
MySourceCrawlerRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: 'Allow'
Principal:
Service:
- 'glue.amazonaws.com'
Action:
- 'sts:AssumeRole'
Path: '/'
Policies:
- PolicyName: 'root'
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- 'glue:*'
Resource: '*'
- Effect: Allow
Action:
- 'logs:CreateLogGroup'
- 'logs:CreateLogStream'
- 'logs:PutLogEvents'
- 'logs:AssociateKmsKey'
Resource: '*'
- Effect: Allow
Action: 's3:ListBucket'
Resource: !GetAtt MySourceDataStore.Arn
- Effect: Allow
Action: 's3:GetObject'
Resource: !Sub
- '${Bucket}/*'
- { Bucket: !GetAtt MySourceDataStore.Arn }
MySourceCrawler:
Type: AWS::Glue::Crawler
Properties:
Name: my-source-data-crawler
Role: !GetAtt MySourceCrawlerRole.Arn
DatabaseName: !Ref MySourceGlueDatabase
Targets:
S3Targets:
- Path: !Ref MySourceDataStore
SchemaChangePolicy:
UpdateBehavior: 'UPDATE_IN_DATABASE'
DeleteBehavior: 'LOG'
SourceCrawlerLakeGrants:
Type: AWS::LakeFormation::Permissions
Properties:
DataLakePrincipal:
DataLakePrincipalIdentifier: !GetAtt MySourceCrawlerRole.Arn
Permissions:
- ALTER
- DROP
- CREATE_TABLE
Resource:
DatabaseResource:
Name: !Ref MySourceGlueDatabase
DatalakeLocation:
Type: AWS::LakeFormation::Resource
Properties:
ResourceArn: !GetAtt MySourceDataStore.Arn
RoleArn: !Sub arn:aws:iam::${AWS::AccountId}:role/aws-service-role/lakeformation.amazonaws.com/AWSServiceRoleForLakeFormationDataAccess
UseServiceLinkedRole: true
Add the above resources to your datalake.yml file and run an update stack command.
aws cloudformation update-stack --stack-name my-source-glue-stack --template-body file://datalake.yml --capabilities "CAPABILITY_NAMED_IAM"
When you have deployed the crawler, you should be able to see and run it in the Glue Console.
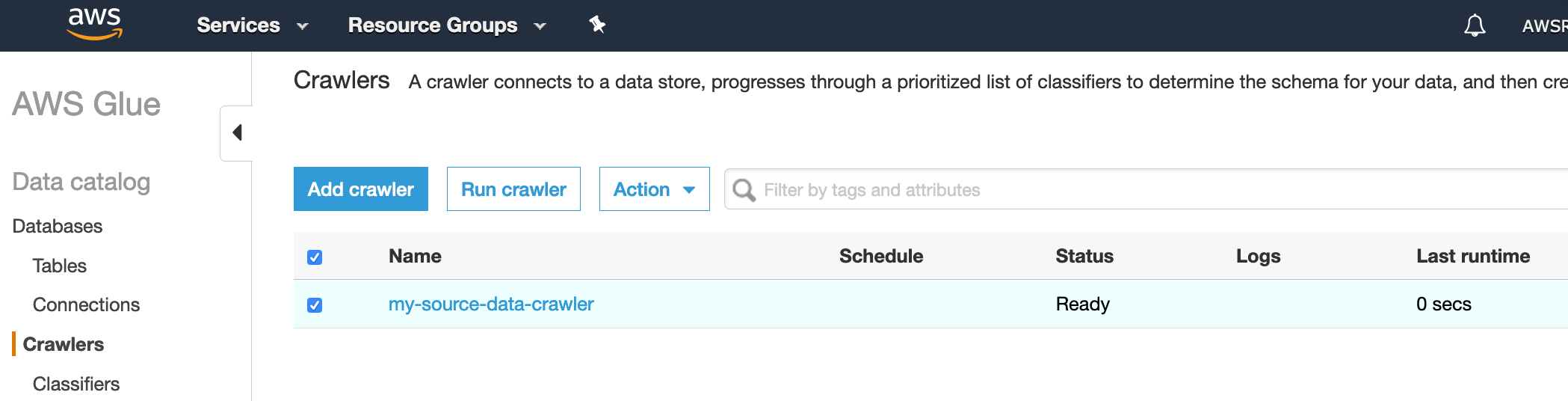
Click on run and wait for your crawler to be completed.
Once your crawler runs successfully, you can go to tables menu item and see your table being generated.
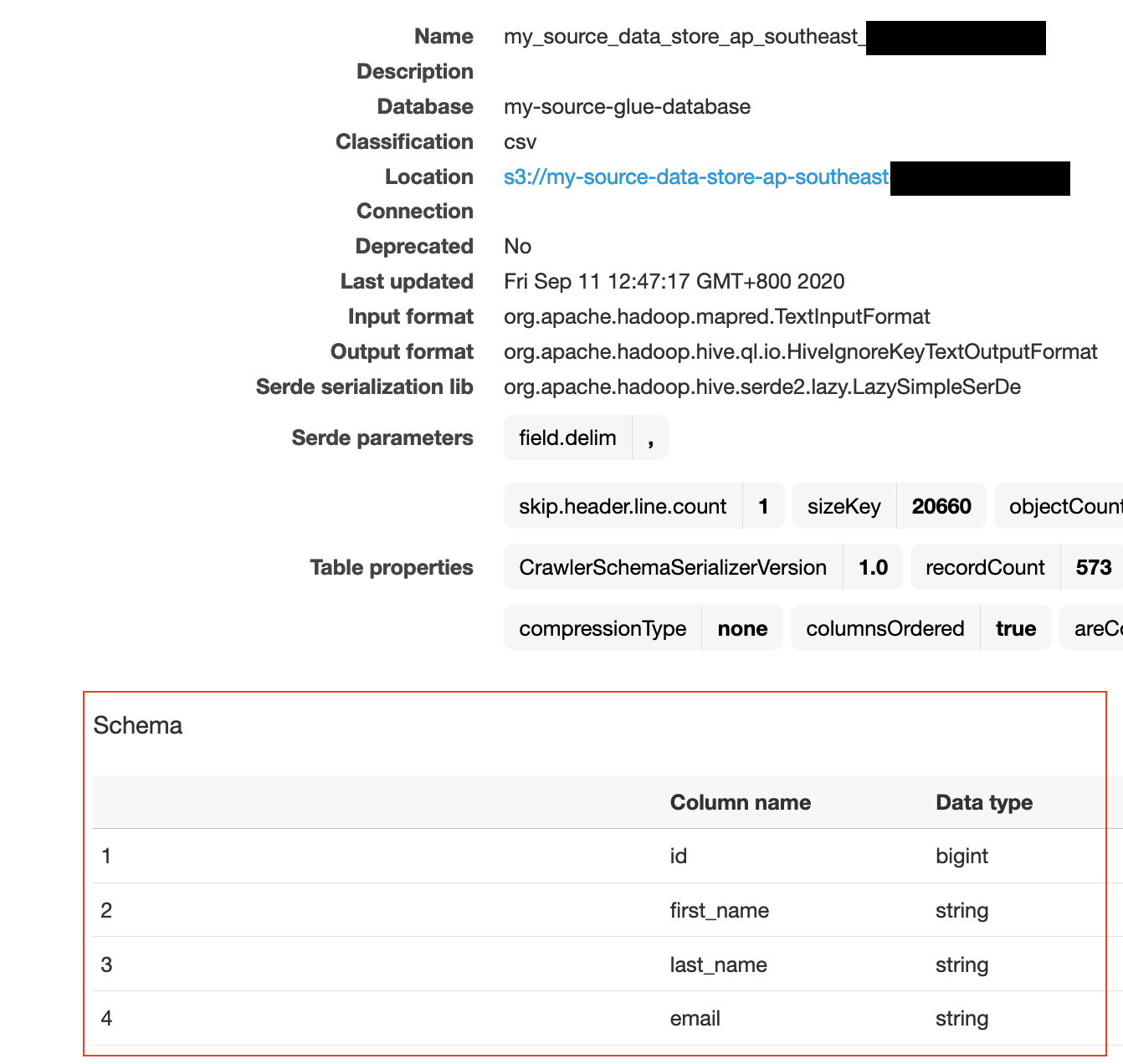
Cross-account grant
Once you have your Glue database and tables created, you will be able to manage the database access via Lake Formation.
To enable cross-account access, you will need to add a Lake Formation grant and specify the consumer account number.
CrossAccountLakeGrants:
Type: AWS::LakeFormation::Permissions
Properties:
DataLakePrincipal:
DataLakePrincipalIdentifier: "300000000015" # Consumer account number
Permissions:
- SELECT
PermissionsWithGrantOption:
- SELECT
Resource:
TableResource:
DatabaseName: !Ref MySourceGlueDatabase
Name: !Sub 'my_source_data_store_ap_southeast_2_${AWS::AccountId}'
# TableWildcard: [] # WildCard is not available via cloudformation yet
This will automatically create a resource share with AWS Resource Access Manager (RAM), and the administrator will see the shared database in their Glue Catalog.
Setting up permissions in the consumer account
We have shared the table from the source account to the consumer account. But, by default only the administrator of the consumer lake will have access to those shared resources. To enable other IAM users or roles to access the resources, we’ll need to create grants.
Login into the consumer account and setup Lake Formation base settings:
1) Setup a Lake Formation administrator:
AWSTemplateFormatVersion: '2010-09-09'
Description: My consumer data lake setup
Resources:
LakeformationSettings:
Type: AWS::LakeFormation::DataLakeSettings
Properties:
Admins:
- DataLakePrincipalIdentifier: arn:aws:iam::300000000015:role/aws-reserved/sso.amazonaws.com/AWSReservedSSO_AWSAdministratorAccess_56cabj890003333
2) Turn on Lake Formation grants:
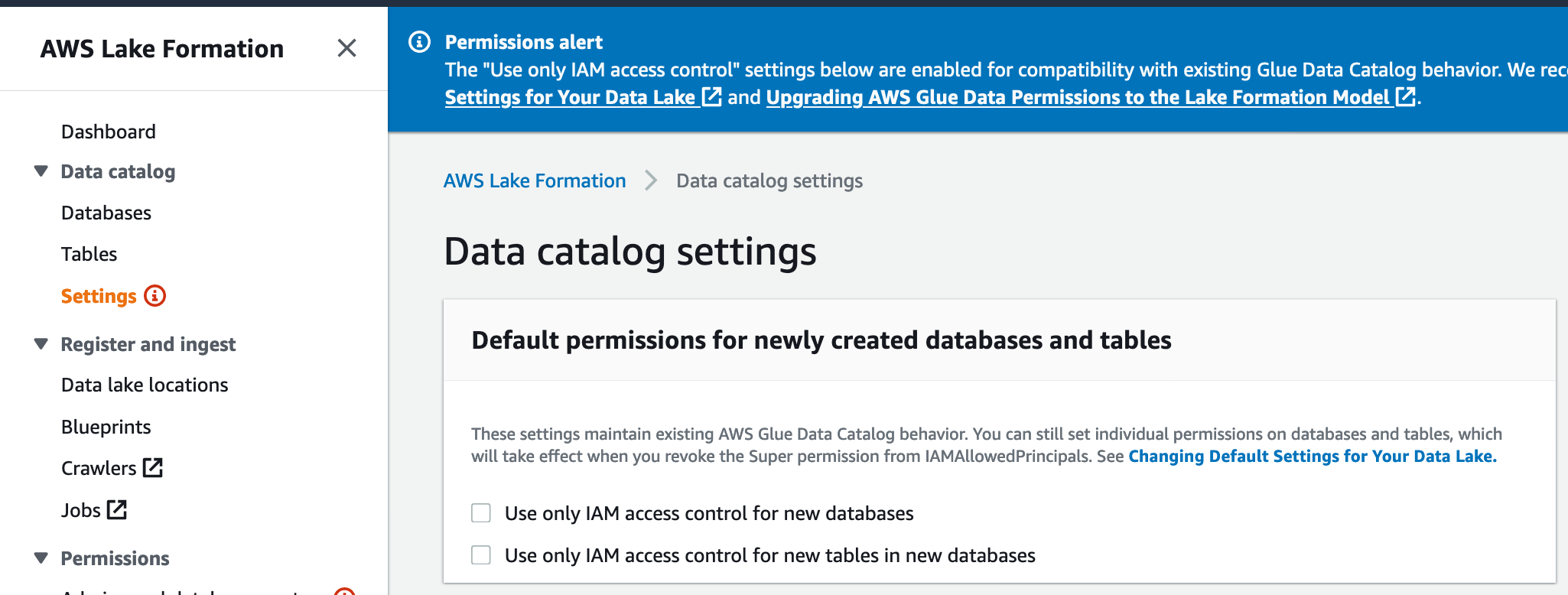
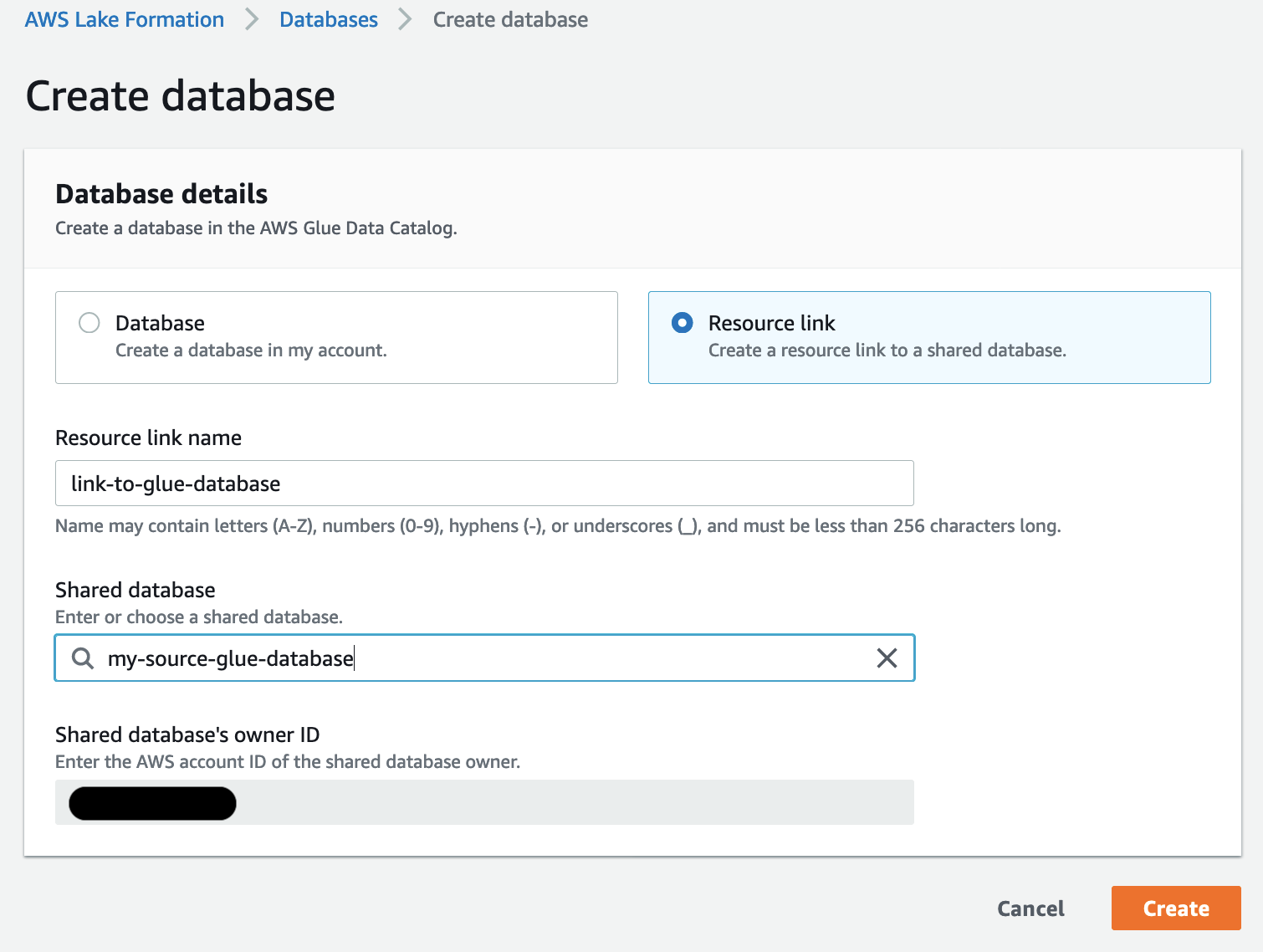
Now you need to create a resource link to the database in the data lake account. Unfortunately, this is not available via CloudFormation yet. In Lake Formation console, click on databases -> create database button
Choose a name for your link database and select the shared database from the list. If you have shared a single table instead of all tables, database name does not appear here. In that case, you will need to create a resource link table.
[https://docs.aws.amazon.com/lake-formation/latest/dg/create-resource-link-table.html]
Next you need to grant access to your role to be able to select from the table:
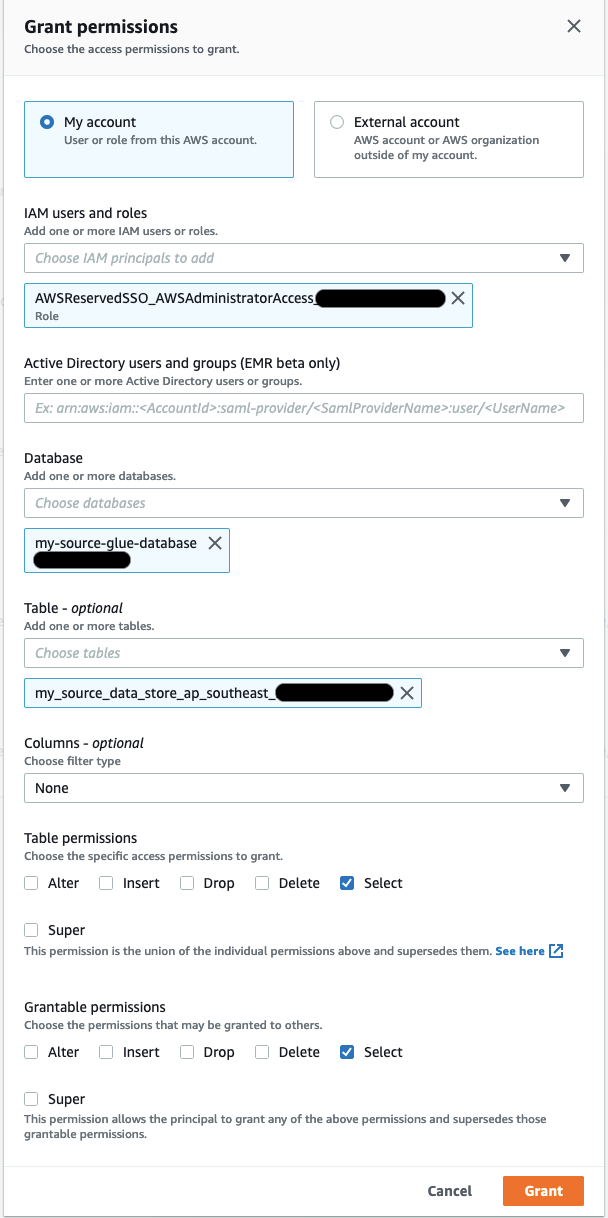
This is quite a powerful feature because it enables the administrator of each account’s lake to have full control over access to that lake. That also applies to resources that are shared from other accounts.
Testing the access in the consumer account
Open Athena from the console.
Note: If you have never used Athena in your account, you will need to create a s3 bucket and set it as your query result location in settings for Athena.
Once you open Athena console, you should be able to see your like database and table schema. Now all there is to do is to query the table and make sure it returns the result.
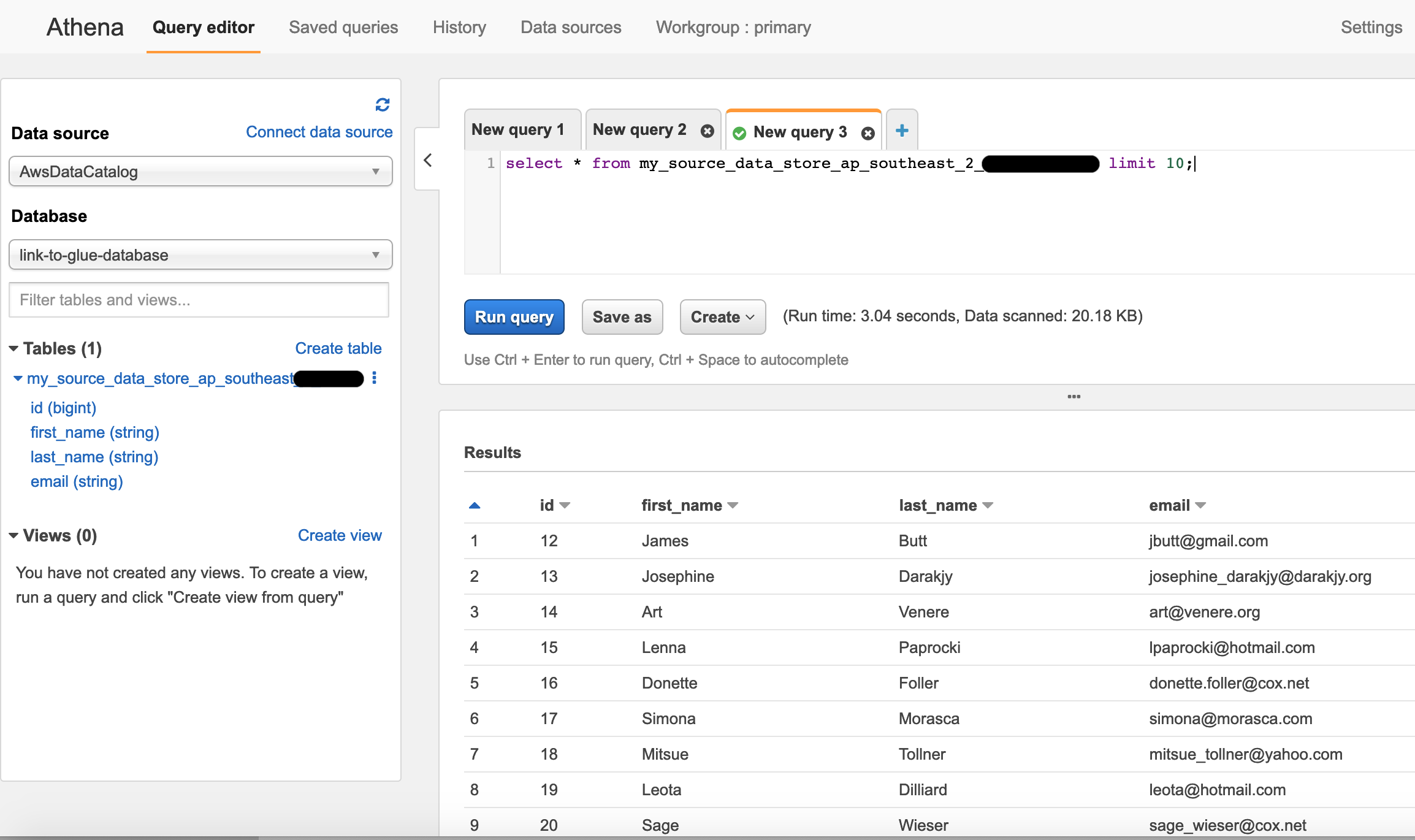
Summary
In this post we learnt how to manage cross-account access to a data catalog with Lake Formation. This enabled us to query a data store from another account, without compromising on security.
If we used AWS Glue on its own, we would have created bucket policies, catalog policies, and IAM policies. This would have required knowledge of the underlying data storage in S3. These are details we don’t want to worry about.
Lake Formation simplifies this by creating a single layer of access control through grants. Shared resources appear in the data catalog of the consuming account, resulting in a seamless experience.
Thanks for reading this introduction to Lake Formation. If you would like to learn more about cross-account data patterns, feel free to get in contact with us.