Automating Serverless Streaming Data Analytics in AWS with Kinesis Analytics
Tags: aws kinesis realtime analytics cloudformation
Building data processing pipelines with streaming data in the cloud can be complex and expensive to run at scale, let alone implementing an efficient and manageable development process. Today we will go through how to streamline your development and deployment of AWS Kinesis Analytics applications with DevOps best practices. We will walk through how to build and deploy an application by using an automated CI/CD process, all around a serverless infrastructure, so taking away the need to manage servers and their administration, we just focus on our application code development with what data processing techniques we want to apply. The example application we will use is one also used by AWS documentation and tutorials, how to perform near-realtime analytics on a data stream producing stock trading data (Event Time, Ticker-ID, $Price). For reference to all the code, you can get it from our Github Repository: Kinesis Analytics Application and Infrastructure
Why Analytics in Realtime? (near real-time when it comes to cloud integration)
- Real-time analytics allows businesses to get insights and act on data immediately or soon after the data enters their system, allowing you to run high performance analytics on streaming data which elastically scales to keep up with the volume of data being ingested.
- Real-time Analytics applicatons can answer queries or process data within seconds. … For example; Financial Investors may want their own/custom analytics applied to live data being generated by the stock exchange, to help make informed trading decisions on whether to buy or sell a stock. A scenario which we will use in our example below.
AWS Cloud Technology Stack and Environment
Amazon Kinesis Data Analytics is serverless, there are no servers to manage and no minumum fee or setup costs, just the resources the application uses when its running. It runs your streaming applications without requiring you to provision or manage any infrastructure. AWS Kinesis Analytics automatically scales the infrastructure up and down as required to run your applications with low latency.
Kinesis Data Streams will be configured as the Input and Output of the Kinesis Analytics Pipeline, giving you the option in the future to add additional consumers to the output stream as well as Kinesis Firehose which can use the output stream as a source so it can then persist the data directly to a datastore.
Everything is written and defined as code. Cloudformation being the Infrastructure as Code tool, along with GitHub, Codepipeline, CodeBuild and KMS to make up the CI/CD components. The Kinesis Analytics Apache Flink Java application will then be compiled with the jar artifact published to an s3 bucket which is where Kinesis Analytics launches the Flink Java application from. Any updates to the applications pushed to the Github repo will trigger a new build and publish to S3, which Kinesis analytics will apply as an update to your active streaming data-pipeline.
Performance, Throughput and Scaling capabilities of AWS Kinesis Services used
Kinesis Data Streams
Max size of Payload = 1MB
- 1 Shard = 1MB/s Input, 1000 Puts/Sec. 2MB/s Output.
- 2 Shards = 2 MB/s Input, 2000 Puts/Sec. 4MB/s Output.
Kinesis Firehose Delivery Stream:
- Autoscales the input from producers, no need to workout shards or throughput. A source for Kinesis Firehose can also be a Kinesis Data Stream
- Buffering configurable by Kinesis Firehose. Buffer Size and Buffer time(How long you want to keep the buffer in before persisting it)
- Transformations can be performed with Kinesis Firehose and Lambda before persisting to your data store/lake/warehouse. This method is good if your transformations are simple or you have small scale data-processing requirements which would be overkill for Kinesis Analytics (Apache Flink or SQL runtimes).
Kinesis Analytics
Kinesis Analytics is a serverless platform to analyze streaming data with on the fly ETL(Extract, Transform, Load) and data processing operations near real-time! Giving your data pipelines the legs it needs without having to worry about how many legs you need to provide it while also reducing the complexity that most other data pipelines come with.
When taking the serverless journey with kinesis analytics, like many other serverless or managed service products on AWS you should have a good idea on your data throughput, storage and performance requirements to help you manage costs and scaling. Kinesis Analytics provisions capacity as Kinesis Processing Units (KPU), where 1 KPU is equal to 1vCPU and 4GB Memory/RAM. For Apache flink applications where 1 KPU is used, you will get 50GB of storage to run your application which includes the use of checkpoints(having backups of the application) and temporary scratch storage you may want to build into your streaming ETL/Data Processing application.
Kinesis Analytics Application Example: Ingesting/streaming live stock trading data into Kinesis Analytics
Our application will be ingesting stock trading data for ‘AMZN’, ‘GOOG’, ‘AZRE’, ‘ORCL’ and ‘BABA’ with their dollar values at a point in time from a Kinesis Data Stream, which the AWS Kinesis Analytics service will use as a source to perform analytics near real-time. We will use a python script to simulate the generation and streaming of data which will randomly generate stock trading prices every second to a kinesis data stream endpoint. The Kinesis Analytics runtime option we’ll be using is Apache Flink, which will use a sliding time window of 1 minute to get the highest(max operator) price the stock was traded during that time window and output the results to another kinesis data stream.
Data Generator for stocks being traded
import sys
import json
import boto3
import random
import datetime
import time
kinesis = boto3.client('kinesis')
stocks = ['AMZN', 'GOOG', 'AZRE', 'ORCL', 'BABA']
stream = 'stocktrading-ingest-stream'
def genData(cloudPlatform):
data = {}
now = datetime.datetime.now()
str_now = now.isoformat()
data['EVENT_TIME'] = str_now
data['TICKER'] = random.choice(stocks)
price = random.random() * 100
data['PRICE'] = round(price, 2)
return data
tradingVolume = 0
while tradingVolume <= 100000:
for cloudPlatform in stocks:
data = json.dumps(genData(cloudPlatform))
kinesis.put_record(
StreamName=stream,
Data=data,
PartitionKey="partitionkey")
time.sleep(1)
tradingVolume += 1
Basic Streaming Job with Apache Flink
The Apache Flink Java application is a basic example with the source under the /src folder called BasicStreamingJob.java
package com.amazonaws.services.kinesisanalytics;
import com.amazonaws.services.kinesisanalytics.runtime.KinesisAnalyticsRuntime;
import com.amazonaws.services.kinesisanalytics.flink.connectors.producer.FlinkKinesisFirehoseProducer;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.JsonNode;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kinesis.FlinkKinesisConsumer;
import org.apache.flink.streaming.connectors.kinesis.FlinkKinesisProducer;
import org.apache.flink.streaming.connectors.kinesis.config.ConsumerConfigConstants;
import org.apache.commons.lang.StringUtils;
import org.apache.commons.lang3.RandomStringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.Map;
import java.util.Properties;
/**
* A basic Kinesis Data Analytics Java Flink application with Kinesis data
* streams as source and sink.
*/
public class BasicStreamingJob {
private static Logger LOG = LoggerFactory.getLogger(BasicStreamingJob.class);
private static Properties appProperties = null;
private static final ObjectMapper jsonParser = new ObjectMapper();
public static void main(String... args) throws Exception {
// set up the streaming execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
appProperties = getRuntimeConfigProperties();
DataStream<String> input = getSourceFromKinesisDataStream(env);
input.map(value -> { // Parse the JSON
JsonNode jsonNode = jsonParser.readValue(value, JsonNode.class);
return new Tuple3<>(
jsonNode.get("EVENT_TIME").asText(),
jsonNode.get("TICKER").asText(),
jsonNode.get("PRICE").asDouble());
})
.returns(Types.TUPLE(Types.STRING, Types.STRING, Types.DOUBLE))
.keyBy(1) // Logically partition the stream per stock ticker id
.timeWindow(Time.seconds(60), Time.seconds(30)) // Sliding window definition
.max(2) // Calculate the maximum value over the window
.map(value -> value.f0 + " ==> " + value.f1 + " : Stock Value: " + value.f2.toString() + "\n")
.addSink(createKinesisDataStreamSink());
env.execute("Flink data stream processing for live stock trading");
}
// Consume from kinesis datastream
private static DataStream<String> getSourceFromKinesisDataStream(StreamExecutionEnvironment env) {
LOG.info("Starting to consume events from stream {}", appProperties.getProperty("inputStreamName"));
String region = getAppProperty("aws.region", "");
String inputStreamName = getAppProperty("inputStreamName", "");
Properties inputProperties = new Properties();
inputProperties.setProperty(ConsumerConfigConstants.AWS_REGION, region);
inputProperties.setProperty(ConsumerConfigConstants.STREAM_INITIAL_POSITION, "LATEST");
return env.addSource(new FlinkKinesisConsumer<>(inputStreamName, new SimpleStringSchema(), inputProperties));
}
// Output Processed/Transformed data to kinesis datastream
private static FlinkKinesisProducer<String> createKinesisDataStreamSink() {
String region = getAppProperty("aws.region", "");
String outputStreamName = getAppProperty("outputStreamName", "");
String aggregation = getAppProperty("AggregationEnabled", "");
String DefPartition = getAppProperty("Partition", "");
Properties outputProperties = new Properties();
outputProperties.setProperty(ConsumerConfigConstants.AWS_REGION, region);
outputProperties.setProperty("AggregationEnabled", aggregation);
FlinkKinesisProducer<String> sink = new FlinkKinesisProducer<>(new SimpleStringSchema(), outputProperties);
sink.setDefaultStream(outputStreamName);
sink.setDefaultPartition(DefPartition);
return sink;
}
// helper method to return runtime properties for Property Group TradingDataConfigProperties defined in Cloudformation Template
private static Properties getRuntimeConfigProperties() {
try {
Map<String, Properties> runConfigurations = KinesisAnalyticsRuntime.getApplicationProperties();
return (Properties) runConfigurations.get("TradingDataConfigProperties");
} catch (IOException var1) {
LOG.error("Could not retrieve the runtime config properties for {}, exception {}", "TradingDataConfigProperties", var1);
return null;
}
}
private static String getAppProperty(String name, final String defaultValue) {
return appProperties.getProperty(name, defaultValue);
}
private static int getAppPropertyInt(String name, final int defaultIntValue) {
final String stringValue = getAppProperty(name,null);
if(stringValue == null){
return defaultIntValue;
}
return Integer.parseInt(stringValue);
}
}
Kinesis Analytics CI/CD Process
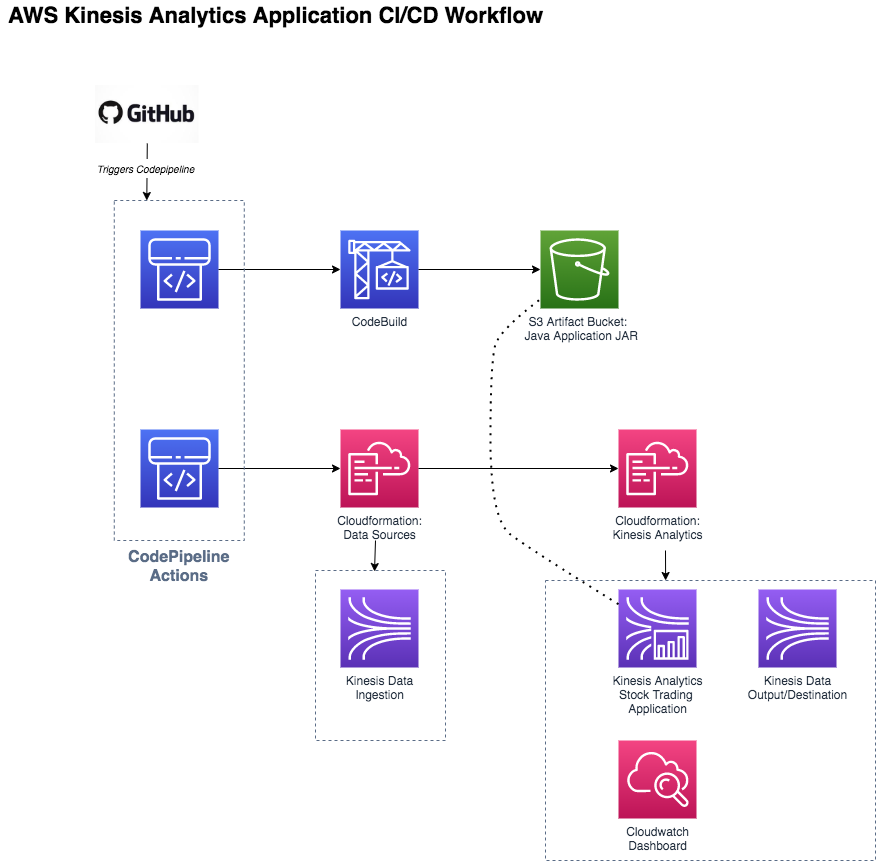
The core component of this CI/CD process is how you maintain the Kinesis Analytics Apache Flink Java application. Any updates to the source code of the Flink Java application will trigger a new build where the artifact produced gets tagged with the Git commit hash and uploaded to the S3 bucket that the Kinesis Analytics service is monitoring. So everytime there is a new build, Kinesis Analytics will automatically update the active streaming data pipeline with the new version automatically.
Take note that there are properties in the Flink Java application which reference parameters set in the cloudformation template, which means that in the Java Application there is a helper method called “getRuntimeConfigProperties” which looks up specific parameters defined in the cloudformation template. The benefit of this means less churn and development iteration on your core kinesis analytics application, so if there are changes to AWS stream names, AWS regions, Aggregation properties or Partition properties, you just update the cloudformation template and the application will detect and apply the changes.
Also included as part of the deployment in cloudformation is a cloudwatch dashboard to monitor the kinesis data streams and performance.
Application Source and Infrastructure as Code templates for your reference can be found at the following Mechanical Rock Github repo: Kinesis Analytics Application and Infrastructure . Keep note that for the AWS Deployment process, we are deploying cross-account, separating the Workload Account(Sandox in this case) from the Tooling/Build account, which helps keep it more secure and if someone does make a boo-boo, the blast radius is reduced to impact a single account.
AWS Kinesis Data Analytics Architecture
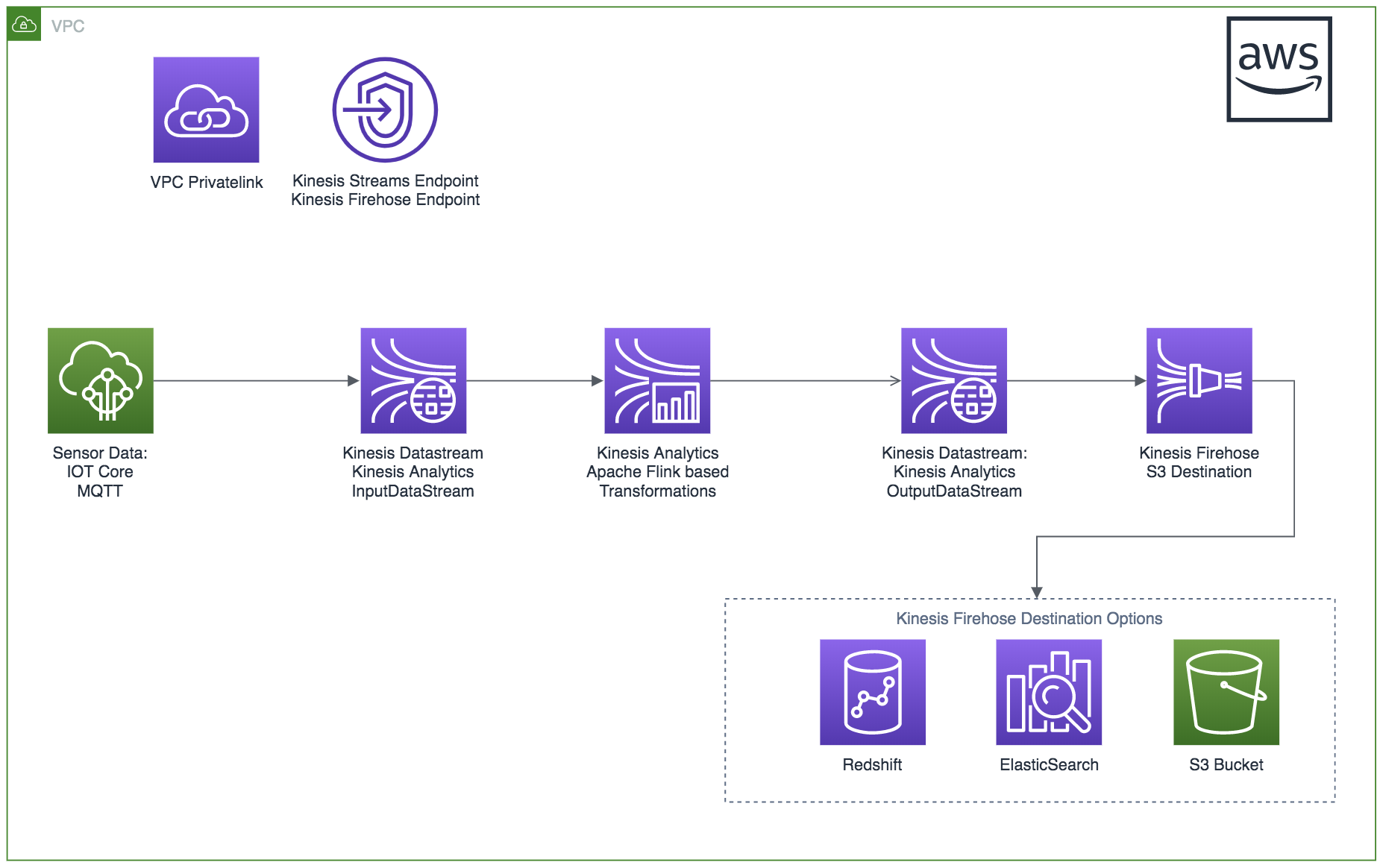
The above Architecture diagram for streaming data analytics in AWS shows how flexible we can be with data sources (data producers), data consumers and how we can persist data in AWS. Having the “processed” data output to another Kinesis Data stream gives you the option of adding additional consumers down the track for new requirements, as well as piping it to Kinesis Firehose to persist the data into Redshift, S3, ElasticSearch, HTTP Endpoints, Datadog, Splunk and more, without having to change the core architecture of how you ingest the data and perform near real-time analytics.
The example we went through today should hopefully provide you with the foundations you need to build your serverless streaming data analytics solution, with a CI/CD platform that lets you focus more on the data analytics part of the problem you are trying to solve.. Leaving you with lots of choices and fun without getting stuck in the weeds of infrastructure. You now have more time to work on improving or enhancing your streaming data analytics in AWS, rather than having to wrangle server infrastructure to process your streaming jobs efficiently and scale… and remember to apply the K.I.S.S principle “Keep it Serverless Stupid”