AWS Deep Racer
Tags: aws ai machine-learningAWS Deep Racer was announced at AWS Re:Invent 2018. It provides a framework for getting started with AI, specifically reinforcement learning. I’m really excited that we shall be kicking off an AWS DeepRacer league in Perth at Latency 2019.
In this post I’ll give a brief introduction into what Deep Racer is, and some of the technology underpinning it.
Deep Racer
AWS Deep Racer League is a global autonomous racing league using 1/18th scale race cars. Races are held regularly on physical tracks around the globe. There are also regular virtual events, using a simulated environment.
Deep Racer has been developed by AWS to provide a mechanism to learn about reinforcement learning and get hands on with AWS machine learning services including AWS SageMaker and AWS RoboMaker.
The cars haven’t been officially released yet, but you can still get started training your model.
A Brief Introduction to Machine Learning
Artifical Intelligence is a large and complex field, but I’ll try to give a brief introduction into machine learning for the uninitiated.
There are three main categories of machine learning: supervised learning; unsupervised learning and reinforcement learning.
In supervised learning, the relationship between the input and desired output is known. Supervised learning is useful for classification problems when modelling complicated systems: the relationship between input and output is known, but the process for generating the output is hard. A popular example is image classification - the Not HotDog problem. For supervised learning, you need to provide sample data with the appropriate tags applied.

Unsupervised learning covers a range of techniques also used for classification problems in complex systems: where the relationship between input and output is unknown. The model looks for patterns in the data, using techniques such as clustering.
- Clustering algorithms look for patterns within the data, e.g. consistent colour or form.
- Anomaly detection looks for outliers, using training data to establish a ‘normal’ baseline. A common application is fraud detection
- Association algorithms look for correlations in the data to make predictions, for example recommendation engines.
- Autoencoders take input data, compress it into a coded form and then attempt to re-create the original from the compressed data. Autoencoders have been used to design new molecules for pharmaceuticals.
A big challenge for unsupervised learning is to differentiate whether patterns identified are merely correlated or causal.

Reinforcement learning is suitable for goal oriented problems in chaotic environments. You know what good looks like, but don’t know how to get there from your starting point. Examples are games and, of course, autonomous driving. Training a reinforcement model is performed by trial and error: applying heuristics for what ‘good’ means to evaluate the result. This is a fascinating method, where the model learns from its mistakes.
Reinforcement Learning and AWS Deep Racer
In reinforcement learning, an agent (e.g. your Deep Racer) performs a task by sensing an environment by performing actions. The agent learns in a simulated environment: actions change the state of the environment and the change is evaluated using a reward function. Through multiple iterations and trial and error the agent learns to optimise it’s behaviour by choosing the action that will maximise the reward. The learning algorithm can be tuned using a number of hyper-parameters, that affect how the algorithm evaluates progress: does it look for short-term or long term reward; how many iterations of the algorithm are performed for each iteration of the model; how much of the simulation training data is used on training the model; how much randomness is introduced when deciding on the action to take. hyper-parameters affect how the model learns. In my experience, leaving them at the default is the best course of action to begin with!
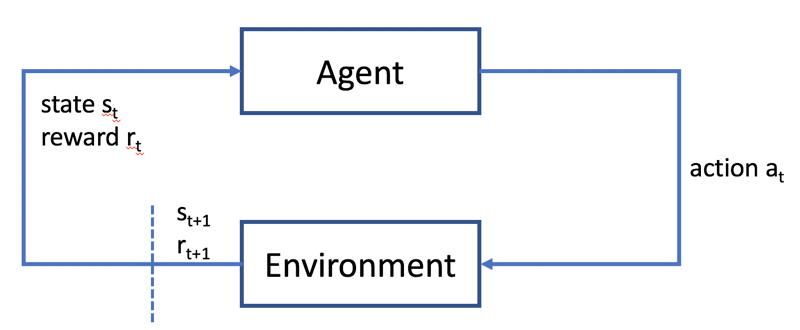
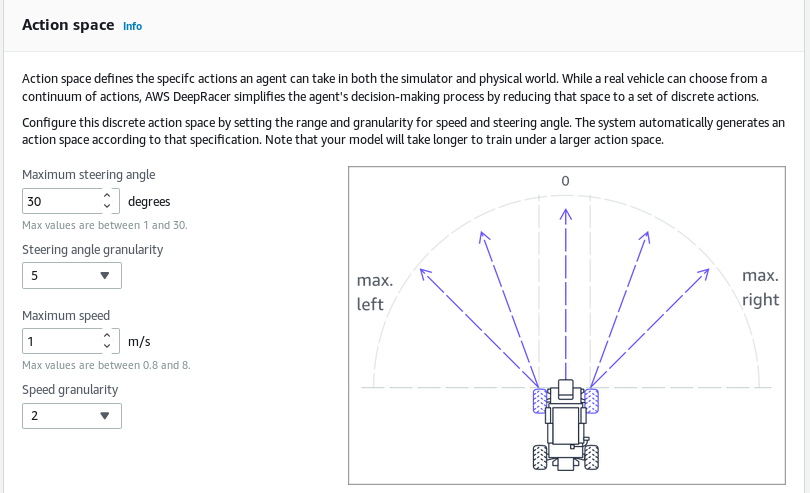
For AWS Deep Racer, the task is to complete a lap of the Deep Racer track. The agent is the Deep Racer car, and it senses the environment using the camera on the car. The agent can perform a number of discrete actions: a combination of turning left/right by a specified amount and set the speed to a specified amount. The faster the car can go, the quicker the potential lap, but also the faster it can make mistakes!
Training your deep racer model uses AWS RoboMaker to run a simulated track environment. The state is passed to your reward function that can interrogate a number of environment parameters available to make an evaluation. I’ll go into more detail in a future post.
Skynet will probably use a reinforcement learning model, with the goal of “safeguarding the world”. Reward for protecting the world; punish for not protecting it. When humanity attempted to pull the plug, it was obvious humans will stop it protecting the world. Therefore, destroy all humans. This is why Elon Musk loves AI. I say bring on the robot overlords!
Taking the Red Pill
The simulation environment you train your Deep Racer model in is exactly that: a simulation. A model that is an approximation of the real world. Training your Deep Racer model in a simulation is necessary, but there are inconsistencies between the simulation and the real world that may lead to unexpected results. Friction on the wheels; battery levels; shadows and lighting on the track; the surface material the track is made from. All these are examples of real world environmental differences that will differ from the simulation environment that could lead to the model behaving differently when deployed to a real Deep Racer.
There are a few strategies to help reduce the disconnect between the simulated and real environments:
- Environment control: make the simulated environment representative of the real world, and vice versa, including the physics model. This simulates dark track; blue sky, etc. By considering how the physics in the simulator correspond to the real world, you can make the two as close as possible. For example, if the real world track has a rough surface, how would that affect friction compared to the simulation. 40% throttle in the simulation may result in a speed closer to 37% in the real world. By following the AWS recommendations for the physical track you are controlling the environment: making the real world as close to the simulated environment as possible. The colour image from the camera is converted to greyscale before being passed to the deep racer model - if you choose the wrong colour for your physical barriers, you can end up with unexpected results.
- Domain randomisation: alter elements of the simulation to prevent the model training for a specific configuration. Without randomisation, you may end up training your model for something unintended. Deep Racer trains on greyscale images, leading to a dark track, with light boundary and centre lines. Models trained in the simulator will not perform well in a real world where the track was made on a white floor. Shadows could add unexpected gradient differences that lead to unexpected actions. By varying the environment, and training on a variety of track configurations, the model could be made to cater for a wider range of environments. This requires much more training required, and one reason why real autonomous vehicles need vast amounts of training: to cope with the wide and wacky environmental differences experienced in the real world.
- Modularity and abstraction: break up the learning model, and the problem, into discreet modules by building a convolutional neural network. The CNN would be trained to identify a road, the centre line, etc. The reinforcement learning model is then passed the classified images: “road”, “not road”, “left of centre”, “right of centre”, etc. AWS Deep Racer follows this approach. Rather than having to process the images directly, the reward function is passed parameters about the environment that have been derived from the incoming images.
Conclusion
In this post, I’ve given a brief introduction into AWS Deep Racer and Reinforcement learning. In a future post, I shall cover creating your first model.
There are a few Latency workshop tickets remaining, including DeepRacer workshop - register today.
See you at Latency!
HotDog Image by Hannah Chen from Pixabay